Editionsrichtlinien
Bei allen sechs Dokumenten wurde eine diplomatische Transkription vorgenommen, d. h. es wurde in den fünf Manuskripten und dem einen gedruckten Text die historische Schreibung so weit als möglich zeichen-, zeilen- und seitengenau übernommen. Insbesondere die Groß- und Kleinschreibungen, die Worttrennungen und Spatien, aber auch die Zeichensetzungen wurden mit einem möglichst geringen Maß an editorischer Interpretation wiedergegeben. In unentscheidbaren Fällen wurde für die heutige Schreibweise optiert.
Um die Lesbarkeit zu erhöhen, sind allerdings editorische Ergänzungen in
allen Texten eingefügt geworden. All diese hinzugefügten Symbole und
editorischen Zusätze können aber in der oberen horizontalen Menüleiste,
die beim Aufrufen der Editionsansicht erscheint, mittels des rechten
Drop-down-Menüs „Anzeigeoptionen“
(Symbol )
aus jeder Seitenansicht entfernt werden. Die zur Verbesserung der
Lesbarkeit von den Herausgeber*innen verwendeten Symbole und
editorischen Zeichen sind selbsterklärend: Ihre Bedeutungen können
mittels des Buttons links in der Menüleiste der Editionsansicht
„Informationen zur Edition“
(Symbol
)
aus jeder Seitenansicht entfernt werden. Die zur Verbesserung der
Lesbarkeit von den Herausgeber*innen verwendeten Symbole und
editorischen Zeichen sind selbsterklärend: Ihre Bedeutungen können
mittels des Buttons links in der Menüleiste der Editionsansicht
„Informationen zur Edition“
(Symbol )
eingesehen werden. Dennoch seien folgende Hinweise gegeben:
)
eingesehen werden. Dennoch seien folgende Hinweise gegeben:
-
Sogenannte Schlenker am Wortende (-en oder -er) wurden ohne Kenntlichmachung ausgeschrieben, auch wenn keine Ansätze von e, r oder n zu sehen sind.
-
Abgekürzte Wörter innerhalb der deutschen Textpassagen sind als solche transkribiert und kodiert; in den meisten Fällen wird deren Auflösung bzw. Erweiterung angeboten. Dazu wurde für eine Beibehaltung der Schreibweise des jeweiligen Autors optiert, selbst wenn diese nicht der heutigen Schreibweise entspricht (so wird etwa „jun.“ zu „juny“, „Oct.“ zu „October“ oder „ent.“ zu „entlich“ erweitert). Über das Drop-down-Menü „Anzeigeoptionen“ kann zwischen der Ansicht mit der abgekürzten Schreibweise und jener mit aufgelösten bzw. ausgeschriebenen Abkürzungen gewählt werden. Einige Abkürzungen, die häufig wiederkehren und selbsterklärend sind, wurden nicht aufgelöst (etwa „Fig./fig.“ für „Figur“).
-
Gleiches gilt für Zusammenschreibungen von Wörtern, wie sie vor allem in Corfeys Manuskript zahlreich vorkommen: In der voreingestellten Leseansicht werden die Wörter entsprechend der gängigen Rechtschreibung getrennt anzeigt; doch kann man für eine Ansicht optieren, die alle Zusammenschreibungen dokumentgetreu zeigt (verdeutlicht durch das Symbol
 ).
Zieht man den Cursor über eine solche Textpassage, werden in einem
schwarz hinterlegten Feld — je nach gewählter Option — die zusammen
oder getrennt geschriebenen Wörter angezeigt.
).
Zieht man den Cursor über eine solche Textpassage, werden in einem
schwarz hinterlegten Feld — je nach gewählter Option — die zusammen
oder getrennt geschriebenen Wörter angezeigt.

- Schrägstriche „/“, die eigentlich für ein Komma stehen, wurden durch Kommata ersetzt, so vor allem in der transkribierten Buchausgabe Sturms von 1719. Siehe zum Beispiel Ansicht 5:

- Dort jedoch, wo Schrägstriche zur Markierung eines Versendes innerhalb einer Inschrift verwendet werden, wurden diese beibehalten. Der Unterstrich zwischen einzelnen Satzteilen in lateinischen Inschriften steht meist für einen mitzudenkenden Zeilenumbruch (etwa bei Corfey). Siehe zum Beispiel Ansicht 13:

- Nicht eindeutig zu identifizierende Buchstaben und Wörter wurden mit einem Fragezeichen als „unklarer Abschnitt“ in eckigen Klammern gekennzeichnet. Siehe zum Beispiel Harrach, Ansicht 4:

-
Vor allem das kleine c in ch und sch wird von einzelnen Autoren (Harrach, Corfey, Neumann) weggelassen: Bei leichten Ansätzen eines c wurde es stillschweigend eingefügt, sonst in spitzen Klammern ergänzt. Auch das kleine e lassen Autoren (vornehmlich Harrach) gerne weg: Es wird in spitzen Klammern ergänzt, wo es zur Sinngebung notwendig ist. Häufig werden u und v sehr ähnlich geschrieben, etwa von Neumann. Auch wird häufig ein v verwendet, wo heute ein u geschrieben würde (etwa bei „vndt“); in solchen Fällen ist die Schreibung v beibehalten worden.
-
Einige Wörter sind in Harrachs Manuskript mit ff geschrieben, obwohl es korrekterweise ft heißen müsste. Wir haben uns für die Beibehaltung von ff und die Ergänzung durch ein t entschieden: So wird etwa S. 475 „öffers“ zu „öffters“ oder S. 488 „schrüfflich“ zu „schrüfftlich“ ergänzt. Da die Handschrift keine deutliche Unterscheidung zwischen „den“ und „dem“ und generell keine konstante Verwendung des Dativs zeigt, wurde fast ausnahmslos „den“ übernommen.
Alle Texte sind in mit der Markup-Sprache XML (Extensible Markup Language) nach den Richtlinien der TEI (Text Encoding Initiative) kodiert worden. Es wird stets empfohlen, in synoptischer Ansicht neben die Transkription die kodierten Versionen zu stellen, ansteuerbar über den Button „‹/›“ (gekennzeichnet als „Zeige xml“). Denn einzelne Textphänomene sind zwar erfasst und kodiert worden, haben aber — um den technischen Aufwand überschaubar zu halten — keine optische Umsetzung erfahren. So sind etwa Besitzstempel in den kodierten Versionen nachgewiesen, erscheinen jedoch nicht in den Seitenansichten.
Pragmatisch wurde hinsichtlich der visuellen Umsetzung des historischen Layouts verfahren, zumal jede Dokumentseite als digitales Faksimile in synoptischer Ansicht neben die Transkription gestellt werden kann. Dazu folgende speziellen Hinweise:
-
Für die Anmerkungen und Verweise, die einzelne Autoren (vornehmlich Corfey und Sturm) in den Marginalien machen, wurde nicht eigens eine Seitenspalte eingerichtet; vielmehr sind diese Informationen in einfach geränderten Sprechblasen untergebracht, die am jeweiligen Zeilenende platziert sind.
-
Listen und Tabellen wurden so weit wie möglich umgesetzt. Bei deren Ansicht empfiehlt es sich, die Fensterbreite innerhalb der synoptischen Bildschirmansicht zu vergrößern, um die Zeilenlänge in Kongruenz zum historischen Dokument anzeigen zu lassen.
-
In den Editionen der Texte von Pitzler, Knesebeck und Neumann sind Zeichnungen und Textpartien miteinander verschränkt; bei Pitzler ist diese Verzahnung äußerst komplex. Die Platzierung der Textpartien in Bezug zu den Zeichnungen wird in der Seitenansicht der Transkriptionen (von wenigen Ausnahmen abgesehen) nicht reproduziert. Zur besseren Strukturierung der Sinneinheiten sind jedoch allen Zeichnungen Bildtitel in eckigen Klammern zugeordnet, die die Bildinhalte identifizieren. Dabei handelt es sich um Zusätze der Herausgeber*innen. Die verwendeten Fachtermini und ihre Abfolge sind vereinheitlicht worden und folgen einem Schema. Das führt manchmal zu einem etwas schwerfälligen Sprachstil, der aber zugunsten einer größeren Einheitlichkeit und Eindeutigkeit der Betitelungen in Kauf genommen wurde. Die zu den Bildtiteln gehörigen Textteile folgen meist auf die Titelgebungen, können aber auch in wenigen Fällen vorausgehen, dort wo das sinngemäßer erschien. Wichtig ist zu beachten, dass die einzelnen Sinneinheiten jeder Seite stets von oben links nach unten rechts innerhalb der Transkription aufeinander folgen.
-
Die im Buch von Sturm unterhalb der Kupferstichtafeln gemachten Angaben zum Entwerfer, Stecher und Verleger der Blätter (Leonhard Christoph Sturm, Johann August Corvinus und Jeremias Wolff) wurden nicht transkribiert.
-
Zahlen und Maßangaben innerhalb der Zeichnungen wurden nur dort wiedergegeben, wo die Übersichtlichkeit der Transkriptionen nicht zu sehr darunter litt. In den Editionen von Sturm und Knesebeck wird auf die fehlenden Transkriptionen der Zahlenangaben in den Zeichnungen durch einen expliziten Hinweis unterhalb der Bildtitel aufmerksam gemacht. Im Manuskript von Pitzler unterbleibt allerdings dieser Hinweis aufgrund der zahlreichen Zeichnungen. Es empfiehlt sich daher ausdrücklich, immer die digitalen Faksimiles ergänzend zu Rate zu ziehen. Oft werden die Maßangaben von den Autoren in Fuß und Zoll angegeben, wobei ein hochgestelltes Häkchen hinter der Zahl (’) „Fuß“ und zwei hochgestellte Häkchen (’ ’) „Zoll“ meint. Allerdings wird dabei nicht genauer angegeben, um welche landesspezifische Maßeinheit es sich handelt (überschlägig gleicht ein Fuß ca. 30 cm, ein Zoll ca. 2,5 cm). Von Ausnahmen abgesehen, haben wir solche Maßangaben nicht weiter kommentiert oder aufgelöst. Das gilt auch für die Längeneinheit „Toise“ (überschlägig ca. 1,95 m). Wenn Corfey keine Maßeinheit angibt, kann man davon ausgehen, dass stillschweigend die letzte vom Autor gemachte diesbezügliche Angabe Anwendung findet.
-
Horizontale und vertikale Linien, wie sie besonders häufig im Manuskript von Pitzler zur Abgrenzung einzelner Zeichnungen vorkommen, sind entsprechend kodiert; allerdings werden nur manche der horizontalen Linien auch visualisiert — immer dort, wo es der Klärung der Seitenorganisation dienlich ist. Eine ebensolche pragmatische Herangehensweise wurde bezüglich der Visualisierung von gepunkteten oder gestrichelten Linien, zentrierten Textpassagen und dergleichen angewandt.
-
Manche Autoren (vornehmlich Sturm und Knesebeck, in wenigen Fällen auch Corfey) fügen eine Silbe oder ein Wort am Seitenende in einer ansonsten freigelassenen Zeile rechtsbündig an, um entweder den Satz zu beenden oder das erste Wort, mit dem die folgende Seite einsetzt, anzugeben. All diese Silben oder Wörter werden in der vorliegenden Edition wiedergegeben und weitgehend positionsgetreu angezeigt.
-
Die Schlussformeln der Briefe (bei Sturm und Neumann) wurden jeweils nach einem einheitlichen Schema angeordnet, selbst wenn das nicht immer mit der Strukturierung der Informationen in den Vorlagen übereinstimmt.
Die fünf Manuskripte sind in deutscher Kurrentschrift geschrieben; das Buch von Leonhard Christoph Sturm wurde in deutscher Frakturschrift gedruckt. Visualisiert werden diese Schriftarten einheitlich durch eine lateinische Schrifttype. Alle Autoren verwendeten jedoch auch die lateinische Schrift, wenn sie fremdsprachige Ausdrücke oder Textpassagen wiedergeben bzw. in ihren Text einstreuen wollten. Dieser Wechsel zur lateinischen Schrift wird in hiesiger Edition durch den Wechsel der Schrifttype innerhalb des laufenden Textes angezeigt. Lateinische Inschriften, etwa auch in römischer Majuskelschrift — wie sie besonders häufig bei Corfey, Knesebeck und Sturm vorkommen —, werden ebenfalls durch den Wechsel der Schrifttype hervorgehoben.
Die von den Autoren wiedergegebenen antiken und zeitgenössischen lateinischen Inschriften von Monumenten und Bauten wurden in der Schreibung nicht korrigiert; lediglich in einigen Fällen wurden falsche oder verkürzte Wiedergaben angemerkt. In den französischen Übersetzungen sind die lateinischen Inschriften dem deutschen Manuskript folgend wiedergegeben. Es sei betont, dass eine durchgängige Übersetzung aller lateinischen (und einiger weniger altgriechischen) Inschriften nicht zu leisten war. Nur in Ausnahmefällen sind solche am Ende einer Inschrift als Anmerkung hinzugefügt.
Die Dokumente beinhalten vereinzelt handschriftliche Zusätze, die nicht von der Hand des Autors stammen, sondern von einem Sekretär oder einem Archivar hinzugefügt worden sind (vor allem bei den Briefen Neumanns ist das der Fall). Diese Zusätze werden zu ihrer besseren Absetzung in einem hellen Grauton angezeigt.
Die rot unterlegte Zahl in der Menüleiste der Editionsansicht zeigt jeweils die aufgerufene Ansicht eines Dokuments an. Durch Anklicken der Pfeile rechts und links der Zahl kann entsprechend vor- und zurückgeblättert werden. Beim Klicken auf die Zahl selbst öffnet sich ein Drop-down-Menü, das eine schnellere Navigation innerhalb des gesamten Dokuments erlaubt.
-
Hinter der Nummerierung der jeweiligen „Ansicht“, die von den Herausgeber*innen jeder Dokumentenseite beigegeben wurde, steht die vom Autor bzw. vom Archiv einer jeder Dokumentenseite zugewiesene Seitenzahl bzw. Foliierung in runden Klammern.
-
Beide Zahlen weichen meist voneinander ab, vor allem dann, wenn bestimmte Seiten im historischen Dokument fehlen (etwa bei Pitzler), oder bestimmte Seiten von den Herausgeber*innen neu zugeordnet wurden (wie etwa bei Neumann), also die vom Archiv vorgenommene Nummerierung durchbrochen wurde.
-
Ergänzende Angaben, etwa ob es sich um recto oder verso eines Blattes handelt, werden in spitzen Klammern als ⟨r⟩ und ⟨v⟩ angefügt und somit als Ergänzung markiert.
Über das Lupensymbol oben rechts auf der Webseite lässt sich die Suchmaschine aufrufen. Sie ermöglicht u. a. die Suche nach genauen Wortfolgen (die in Anführungsstriche zu setzen sind) in allen Editionen, Registereinträgen, Einleitungs- und Begleittexten, nicht jedoch in den Anmerkungen. Die Trefferlisten ermöglichen einfache textometrische Analysen, gewähren also einen rudimentären quantitativen Überblick über die Häufigkeit bestimmter syntaktischer und semantischer Phänomene. Es sei darauf hingewiesen, dass es im Lauf der Jahrhunderte zu Bedeutungsverschiebungen mancher Wörter gekommen ist. Eine wertvolle Hilfe bietet hier das von der Universität Trier online gestellte Deutsche Wörterbuch von Jacob und Wilhelm Grimm. So ist den Herausgeber*innen vor allem aufgefallen, dass etwa das Adjektiv „schlecht“, das in den Editionen siebzigmal vorkommt, nicht immer abwertend gemeint ist, sondern oft in der Bedeutung von „schlicht“ (s. auch https://www.dwds.de/wb/etymwb/schlicht). Für ein besseres Verständnis der deutschen Texte empfehlen wir daher den Nutzer*innen, stets auch einen Blick auf die französischen Übersetzungen zu werfen. Dort sind solche Sinnverschiebungen berücksichtigt.
Zum Zitieren der Editionen bieten sich verschiedene Möglichkeiten:
-
In der oberen horizontalen Menüleiste gelangt man links über den Button „Informationen zur Edition“ zu einer „Zitationsempfehlung für diese Edition“. Zusätzlich sollte die Nummer der „Ansicht“ und der dazugehörigen Seiten- bzw. Folioangabe aufgeführt werden. Dort ist in der Sektion „Metadaten“ der Persistent Identifier (PID bzw. Handle) jeder Edition hinterlegt. Klickt man auf den PID, gelangt man zu der im TextGrid Repository hinterlegten Edition. Diese kann im Format HTML heruntergeladen und als PDF ausgedruckt werden. Im TextGrid Repository können auch die „Voyant Tools“ für eine fortgeschrittene Sprachanalyse der Korpora genutzt werden.
-
Jede einzelne Seite kann aber auch durch das Kopieren der im Browser angegeben URL zitiert werden.
-
Auch jede Anmerkung (ob der Herausgeber*innen oder Übersetzer*innen) wird auf jeder Ansicht beginnend mit „1“ durchnummeriert. Die jeweils zu einer Anmerkung gehörige URL kann entsprechend kopiert werden und als Zitatnachweis dienen.
-
Ebenso kann jeder Registereintrag durch das Kopieren der URL aus der Adresszeile des Browsers zitiert werden.
Wie aus diesen Erläuterungen ersichtlich, bietet die Website dynamische, leicht von den Nutzer*innen ihren jeweiligen Informationsbedürfnissen anpassbare Editionsansichten an. Die Registereinträge und die wissenschaftlichen Anmerkungen bieten zudem den Online-Zugriff auf externe Zusatzinformationen (Bilder, Bücher, Geokoordinaten, Thesauren usw.).
Autor: Hendrik Ziegler
Von den sechs auf der Webseite ARCHITRAVE herausgegebenen Texten sind drei unveröffentlicht (Harrach, Knesebeck und Pitzler); Sturms Text wurde 1719 erstmals als Buch publiziert, Corfeys Tagebuch war 1977 Gegenstand einer ersten kritischen Ausgabe (s. Corfey 1977) und die Briefe Neumanns wurden in ihrer deutschen Fassung bereits 1911 und 1955 herausgegeben (s. Lohmeyer 1911 und Freeden 1955). Ein zentrales Anliegen unseres webbasierten Editionsprojekts ist es, eine Übersetzung dieser sechs deutschen Texte vom Ende des 17. und Anfang des 18. Jahrhunderts anzubieten, um sie für die Fachwelt, aber auch für ein interessiertes Laienpublikum zugänglich zu machen. Die Wahl der Sprache fiel für die Übersetzung dieser Berichte deutscher Reisender in ihr westliches Nachbarland selbstredend auf das Französische — zudem im Rahmen eines deutsch-französischen Projekts ANR-DFG, bei dem auf die Expertise eines binationalen Teams zurückgegriffen werden konnte. Die Übertragung ins Französische, die auf einer wiederholten akribischen Lektüre der Originaltexte beruht, um zu einer Klärung der selbst für einen deutschsprachigen Leser oft schwierigen Sinngehalte der Texte zu gelangen, stellt einen der wichtigsten Erträge des Projekts dar.
Allgemeine Herangehensweise und stilistische Besonderheiten der Texte
Bewusst haben wir uns für einen Übersetzungsansatz entschieden, der auf bestmögliche Lesbarkeit abzielt. Bei den hier bearbeiteten sechs Quellen handelt es sich nicht um Texte mit literarischem Anspruch; von ihren Autoren waren sie auch nicht als solche gedacht. Sie sind meist in Alltagssprache geschrieben, bei der das Festhalten einer Information Vorrang vor dessen sprachlich nuancierter Darstellung hat; zudem sind sie in einem Deutsch der Barockzeit verfasst, in einer Orthografie, die noch stark je nach der regionalen Herkunft und dem sozialen Stand des Schreibenden schwankt. Die sechs Texte unterscheiden sich auch hinsichtlich ihres Aufbaus und ihrer Kommunikationsabsicht. Bei der Übersetzung haben wir uns bemüht, so nah wie möglich am Wortlaut des Originals zu bleiben; allerdings haben wir uns bestimmte Freiheiten dort gestattet, wo schwer verständliche Textpassagen zur besseren Verständlichkeit eine Distanzierung erforderten. Auch wurde bewusst für die Anwendung einer modernen Lexik und Syntax optiert, um die Schwerfälligkeiten der Originaltexte nicht unnötig zu reproduzieren. Doch selbst wenn wir der Lesbarkeit und Fluidität der französischen Übersetzungen den Vorrang gegeben haben, so haben wir uns dennoch bemüht, die zeitspezifische Tonalität der Originaltexte so gut wie eben möglich zu bewahren bzw. in den Übersetzungen durch die punktuelle Verwendung eines aus heutiger Sicht antiquierten Vokabulars aufscheinen zu lassen. Angesichts der Uneindeutigkeit bestimmter Passagen ist die Übersetzung zwangsläufig eine Interpretation, wobei die Leser*innen stets die Möglichkeit haben, in der synoptischen Ansicht die Transkription des deutschen Originals neben die französische Übersetzung zu stellen.
Alle sechs Texte hätten aufgrund des Umfangs schwerlich von einer einzigen Übersetzerin oder einem einzigen Übersetzer übertragen werden können. Daher wurden auf der Grundlage einer Ausschreibung und eines Testverfahrens schließlich vier Übersetzerinnen und ein Übersetzer mit der Aufgabe betraut: Anna Hartmann in Zusammenarbeit mit Antoine Guémy (für den Text von Sturm), Isabelle Kalinowski (für Knesebeck), Florence de Peyronnet-Dryden (für Pitzler und Neumann) und Nicole Taubes (für Harrach und Corfey). Die Übersetzungen begannen im April 2016 und waren bis 2021 Gegenstand mehrerer Überarbeitungen. 2019 ist Jean-Léon Muller zum Team der Übersetzer*innen hinzugestoßen.
Es liegt auf der Hand, dass sich mit der wissenschaftlichen Erschließung der Texte, etwa der immer weitergehenden Identifizierung zahlreicher erwähnter Personen, Orte und Werke, auch unser Verständnis der Texte im Laufe der Zeit vertieft hat. Das hatte entsprechende Rückwirkungen auf die Übersetzung — ebenso wie die Übersetzungsarbeit unser Verständnis der Texte entscheidend gefördert hat. Hier war immer wieder eine enge Zusammenarbeit zwischen dem wissenschaftlichen Team (Florian Dölle, Marion Müller, Alexandra Pioch und Hendrik Ziegler) und den Übersetzer*innen notwendig.
Wenn nicht anders angegeben, wurden einige der Zitate und Inschriften in Latein und anderen Sprachen von den Übersetzer*innen der Texte in Zusammenarbeit mit dem wissenschaftlichen Projektteam ins Französische übertragen.
Harrach
Die Tagebuchaufzeichungen von Ferdinand Bonaventura Graf von Harrach sind in einem persönlichen Ton gehalten und damit zugänglicher als die übrigen hier edierten Texte. Der Schreibstil, zwischen nüchterner Referierung des Tagesgeschehens und pointierten Orts- und Personenschilderungen changierend, hat dabei streckenweise literarische Qualität. Es war uns ein besonderes Anliegen, die Lebendigkeit der Schilderungen in der Übersetzung so weit als möglich zu erhalten.
Pitzler
Die Notizen von Christoph Pitzler sind stark additiv aufgebaut, durchsetzt mit zahlreichen Zeichnungen, wodurch sie nicht immer leicht zu lesen sind. Wir haben uns bei der Übersetzung nahe an das deutsche Original gehalten, mussten aber bei weniger klaren Abschnitten auch interpretieren bzw. uns von unserer wissenschaftlichen Intuition leiten lassen.
Corfey
Der Text von Lambert Friedrich Corfey ist leicht zugänglich. Bei Corfeys Aufzeichnungen handelt es sich um ein Reisetagebuch für den eigenen Gebrauch, das nicht für eine spätere Veröffentlichung vorgesehen war. Der Stil ist nüchtern und beschreibend, auch wenn der Autor von Zeit zu Zeit erzählende Passagen und Anekdoten einfügt, die seine Schilderungen lebendig werden lassen.
Wir haben uns daher für eine Übersetzung entschieden, die dem deutschen Text recht nahe kommt. Der Text beinhaltet im Übrigen zahlreiche lateinische Inschriften, die Corfey an Bauwerken und Monumenten entziffert und notiert hat: Wir haben uns darauf beschränkt, nur einige von ihnen zu übersetzen, insbesondere diejenigen, die bereits von Helmut Lahrkamp ins Deutsche übertragen wurden (s. Corfey 1977).
Auf den Ansichten 64 bis 68 (Seiten 67-71) wurden die Namen der französischen Regimenter, die am Manöver in Compiègne beteiligt waren, vereinheitlicht (moderne Typografie und Schreibweise). Auf den Ansichten 140 bis 142 (Seiten 143-145) haben wir die Liste der Schleusen des Canal du Midi so belassen und in den Anmerkungen die gegenwärtigen Bezeichnungen angegeben, soweit diese gefunden werden konnten. Auf Ansicht 172 (Seite 175) wurde die Liste der Schiffsnamen nicht modernisiert, da Corfey hier eine am Arsenal in Marseille befindliche Inschriftentafel wiedergibt.
Knesebeck
Der Text von Christian Friedrich Gottlieb von dem Knesebeck steht jenem von Leonhard Christoph Sturm sehr nahe. Knesebeck war Sturms Mitarbeiter in Schwerin von 1711 bis 1719: Wahrscheinlich hat er alte, heute verschollene Reisenotizen seines Vorgesetzten abgeschrieben, entweder in Vorbereitung einer bereits geplanten Veröffentlichung Sturms oder zur Vorbereitung seiner eigenen Reise nach Frankreich zwischen 1711 und 1713. Allerdings unterscheidet sich Knesebecks Manuskript in zahlreichen Punkten von Sturms 1719 erschienenem Buch, denn offensichtlich hat Sturm seinen Text — wie wir ihn in der Rohfassung im Manuskript Knesebecks vorliegen haben — für die Veröffentlichung entschärft und einige seiner darin enthaltenen harschen Urteile über die Künste jenseits des Rheins relativiert.
Wir haben uns bemüht, bei der Übersetzung den Charakter einer Rohfassung, der Knesebecks Manuskript eigen ist, beizubehalten. Diejenigen Textpassagen, die bei Knesebeck und Sturm nahezu identischen Inhalts sind, wurden allerdings in der Übersetzung einander angeglichen.
Sturm
Leonhard Christoph Sturm ist einer der produktivsten Architekturtheoretiker des Barock gewesen. Seine Architectonischen Reise-Anmerckungen, die 1719 erstmals gedruckt wurden, sind das Ergebnis eines durchdachten redaktionellen Prozesses, der die Beigabe von zahlreichen Illustrationen einschloss, die der gezielten Unterstützung seiner Argumentation dienten. In Anbetracht der Bekanntheit dieses Werks haben wir uns vor allem bemüht, den Text für französischsprachige Leser*innen leichter zugänglich und verständlich zu machen. Daher nimmt sich die Übersetzung einige Freiheiten bei der Übertragung von Sturms teilweise sperriger Sprache. Zahlreiche Passagen sind technisch-deskriptiven Charakters. Diese haben wir versucht, verständlich zu machen, vor allem indem wir das heute gängige Architekturvokabular für die Übersetzung verwendet haben: Sturm, der sich gegen eine von ihm empfundene „Französisierung“ der deutschen Sprache zur Wehr setzen wollte, hat für zahlreiche aus dem Französischen abgeleitete Fachtermini von ihm erfundene deutsche Äquivalente eingeführt (z. B. „Säulen-Stuhl“ für „Piedestal“). Diesbezüglich war die Expertise von Anna Hartmann sehr behilflich, die uns ihre kommentierte, für ihre Magisterarbeit erarbeitete Edition der Architectonischen Reise-Anmerckungen zur Verfügung gestellt hat (s. Hartmann 2000).
Sturm hat in seinem gedruckten deutschen Text zahlreiche Passagen aus der Description nouvelle de la ville de Paris von Germain Brice (wahrscheinlich nach der Ausgabe von 1698) in übersetzter Form übernommen und kommentiert. Die von ihm aus dem Buch von Brice übernommenen Abschnitte sind im Druckbild der Buchausgabe von 1719 abgehoben, indem sie fett gedruckt wurden. Diese nicht immer einfach auszumachende typographische Differenzierung haben wir weder bei der Transkription noch bei der Übersetzung übernommen (s. diesbezüglich die Ausführungen im Einleitungstext zum Autor).
Neumann
Balthasar Neumann war ein Architekt von höchstem Rang, auch wenn sich sein Talent noch nicht voll entfaltet hatte, als er seine Schreiben abfasste: Die während seiner Frankreichreise 1723 geschriebenen Briefe sind an seinen Dienstherrn in Würzburg, Fürstbischof Johann Philipp Franz von Schönborn, gerichtet. Neumann bedient sich eines höflich diplomatischen Stils, getragen von seinem aufrichtigen Diensteifer gegenüber seinem Herrn. Es ist nicht immer einfach, dem Argumentationsgang seiner Korrespondenz zu folgen, da es um viele Details der Bauplanung der Würzburger Residenz geht, die zum Zeitpunkt seiner Reise erst in den Anfängen lag (s. diesbezüglich die Ausführungen im Einleitungstext zum Autor). Die Schreibweise des jungen Offiziers und Architekten ist sehr eigenwillig, ebenso sein Gebrauch (oder vielmehr sein Nichtgebrauch) der Interpunktion. Auch weist seine Schreibweise regionale fränkische Besonderheiten auf (Umformung des „P“ zu einem „B“, prominent etwa bei „Baris“ für „Paris“).
Mehr noch als bei den anderen Texten versteht sich die Übersetzung daher als Interpretationsversuch, der darauf zielt, allen Forscher*innen, die genügend mit dem Französischen vertraut sind, gerade für die schwerverständlichen Passagen eine Lesehilfe anzubieten.
Besonderheiten der Darstellung der übersetzten Textfassungen, Syntax, Rechtschreibung und Zeichensetzung
Besonderheiten der Darstellung der übersetzten Textfassungen**
Die französischen Übersetzungen geben einige Aspekte des deutschen Originals nicht wieder: So werden Streichungen, Wiederholungen, Korrekturen oder Ergänzungen der Autoren gleich in ihrer richtiggestellten Version übersetzt und zahlreiche der verwendeten Abkürzungen ausgeschrieben. Alle Anmerkungen in den Marginalien werden jedoch als solche visualisiert, auch einige der interlinearen Textergänzungen, wo dies für die Sinnerschließung notwendig erschien.
Die französische Übersetzung folgt der deutschen Transkription der Texte nicht in Bezug auf die Zeilenumbrüche, reproduziert aber bestmöglich die Sinneinheiten des Originals: So werden Zeilenumbrüche und Leerzeichen, Einzüge und Einrückungen, Listen und Tabellen, die Legenden von Zeichnungen und Skizzen, die Anordnung von Zitaten und lateinischen Inschriften, Striche und horizontale Linien konform zum deutschen Original reproduziert. Unterstreichungen wurden nur dort beibehalten, wo sie dem Aussagegehalt des Textes etwas hinzufügen. Kursivschrift werden nicht wiedergegeben, sofern diese in den deutschen Texten eingesetzt wird, um Fremdwörter oder Textpassagen hervorzuheben, die in lateinischer Schrift abgefasst sind.
Die Schlusspassagen der Briefe mit der Höflichkeitsformel, der Nennung von Ort und Datum und der Unterschrift (bei Neumann und Sturm) folgen nicht streng der Reihenfolge der deutschen Vorlagen, sondern werden in den französischen Versionen nach einheitlichem Anordnungsschema wiedergegeben.
Einige Leerstellen im deutschen Text werden in der Übersetzung beibehalten, z. B. bei Harrach, Ansicht 2 (S. 456), insbesondere dann, wenn der Autor Leerstellen für nachträgliche Hinzufügungen vorgesehen hat.
In der häufigen Ermangelung von Absätzen in den Texten von Neumann und Corfey haben wir bei der Kodierung der übersetzten Textfassungen mittels der Auszeichnung <ab/> und den Attributen „day“ (dem Datum des entsprechenden Briefs oder des Tagebucheintrags) oder „theme“ (wenn es keine Datumsangabe gab) künstliche Unterteilungen eingeführt. Visualisiert wird eine derart eingefügte Unterteilung durch einen Zeilenumbruch, der im deutschen Original nicht vorhanden ist. Diese eigenmächtige Einteilung ermöglichte es jedoch, die französische Übersetzung in Absätze zu strukturieren und erleichtert somit die Lektüre (zu weiteren diesbezüglichen Informationen s. die Kodierungsrichtlinien).
Zeichensetzung und Typografie
In den deutschen Texten ist die Interpunktion oft willkürlich: So kann etwa ein Komma Satzglieder ohne jeglichen logischen Zusammenhang miteinander verbinden (dies ist vor allem bei Harrach der Fall). Um die französischen Texte verständlicher zu machen, haben wir uns für eine sinnvolle Zeichensetzung (Semikolon, Doppelpunkt) entschieden, Sätze getrennt, wo es nötig war, und Punkte an die Satzenden gesetzt. Fehlende Fragezeichen wurden bei Fragesätzen in der Übersetzung hinzugefügt, ebenso Ausrufezeichen bei eindeutig exklamatorischen Sätzen. Abkürzungen wurden aufgelöst, ohne sie zu kodieren, z. B. bei Harrach, Ansicht 16 (S. 470): 122 fl => 122 Florin.
Großbuchstaben sind in den deutschen Texten nicht immer nach einsichtigen Regeln gesetzt worden, selbst am Beginn der Sätze nicht. In den Übersetzungen haben wir die Großschreibung am Satzanfang systematisch wiederhergestellt, auch sonstige aus heutiger Sicht fehlerhafte Klein- oder Großschreibungen korrigiert. Bei der Übersetzung von Sturms Text haben wir allerdings Großschreibungen nicht beibehalten, die nur der Hervorhebung eines Wortes oder Zwischentitels auf der Seite dienen.
Anführungszeichen wurden bei Zitaten gesetzt, ebenso bei Sinnsprüchen und Äußerungen, die als direkte Rede gemeint sind. Lediglich die Übernahmen, die Sturm aus der Description nouvelle de la ville de Paris von Germain Brice vorgenommen hat und Pitzler aus André Félibiens La description du château de Versailles, wurden nicht eigens in Anführungszeichen gesetzt, weil diese indirekten Zitate von den Autoren nicht immer eindeutig gekennzeichnet worden sind.
Kursiv gesetzt sind in der französischen Übersetzung fremdsprachige
Wörter und Ausdrücke, nicht jedoch Werktitel, die bereits optisch durch
das
Piktogramm als solche gekennzeichnet sind, sowie die transkribierten lateinischen
oder griechischen Inschriften.
als solche gekennzeichnet sind, sowie die transkribierten lateinischen
oder griechischen Inschriften.
Alle fünf Manuskripte sind in deutscher Kurrentschrift verfasst, der handschriftlichen Form der deutschen Frakturschrift; hingegen ist das Buch von Leonhard Christoph Sturm in Frakturschrift gedruckt. Die Autoren verwandten auch die lateinische Schrift, wenn sie Wörter, Ausdrücke oder Passagen aus einer Fremdsprache zitierten. Die beiden Schriften wurden in der Transkription durch zwei verschiedene Schriftarten wiedergegeben: Diese Unterscheidung wurde für die französischen Versionen, die nur eine Schriftart verwenden, nicht beibehalten.
Rechtschreibung
In den deutschen Originaltexten sind zahlreiche Eigennamen (von Orten, Personen oder Werken) falsch geschrieben. In den Übersetzungen wurden diese Fehler korrigiert. Bei allen identifizierbaren Orts- und Personennamen haben wir bei den Übersetzungen stets die heute gängige Form verwendet. Manche Eigennamen wurden von den Autoren auch verwechselt. Solche Fehler haben wir ebenfalls in der Übersetzung korrigiert. Knesebeck, Ansicht 39, fol. 18r, zum Beispiel schreibt „Breteville“, meint aber „Breteuil“. In der deutschen Transkription haben wir „Breteville“ belassen und in der Übersetzung mit „Breteuil“ korrigiert; in beiden Fällen verweist der Registereintrag jedoch auf die Gemeinde Breteuil.
Die Namen von Schildern, Geschäften, Gasthöfen oder Hotels sind in den französischen Textfassungen hinsichtlich Orthografie und Groß- und Kleinschreibung standardisiert worden.
Titel französischer Gemälde, Skulpturen, Stiche usw., die im Ursprungstext auf Deutsch angegeben sind, werden in der Übersetzung mit ihrem heute gängigen französischen Werktitel angegeben. Bereits auf Französisch gemachte Titelangaben (vornehmlich von Publikationen und Stichwerken) wurden soweit nötig korrigiert und nach den aktuellen französischen typografischen Regeln vereinheitlicht.
Vokabular
In der Regel wurde „schlecht“ in der Bedeutung von „schlicht“ mit „simple / modeste“ übersetzt — der üblichen Bedeutung dieses Adjektivs in der Barockzeit. Nur in einigen Fällen haben wir im Sinne von „schlecht / falsch / minderwertig“, also „mauvais / faux / moindre“ übersetzt, nämlich in solchen Fällen, in denen offensichtlich ein solches Werturteil ausgesprochen werden sollte.
Wir haben nicht immer auf die Fehler der Autoren beim Verwenden eines französischen Begriffs im deutschen Original hingewiesen.
Das deutsche Wort „Metall“ wurde im Allgemeinen mit „bronze“ übersetzt; nur in einigen besonderen Fällen haben wir uns für die französische Entsprechung „métal“ entschieden (vornehmlich bei Sturm und Knesebeck).
Unleserliche Textabschnitte
Wörter oder Wortgruppen, die im Originalmanuskript unleserlich und in der deutschen Transkription durch ein Fragezeichen in eckigen Klammern [?] gekennzeichnet sind, werden in der Übersetzung in gleicher Weise angegeben, z. B. Harrach, Ansicht 12 (S. 466): „Hans[?] Preuker“. Manchmal wird in der Übersetzung der Zweifel über die Bedeutung des Wortes allerdings nicht ebenso kenntlich gemacht, z. B. Harrach, Ansicht 4 (S. 458): „Körb[?]“ wird ohne Fragezeichen mit „paniers“ übersetzt. Manchmal wird eine Ergänzung oder Korrektur vorgeschlagen, eingerahmt von den Zeichen < >, z. B. Pitzler, Ansicht 115 (S. 167): „prompti[?]<tude>“.
Französische Textabschnitte, Zitate, Fremdwörter
Die im deutschen Original eingeschobenen französischen Textpartien wurden in der Übersetzung in ihrer ursprünglichen Form übernommen, einschließlich der Rechtschreibung und Zeichensetzung; s. Neumann, Ansichten 47 bis 50 (fol. 67r-68v): Empfehlungsschreiben von Baron Pfütschner; Corfey, Ansicht 58 (S. 61): Bericht über eine Hinrichtung. Andererseits wurden die in den Ursprungstexten eingestreuten französischen Wörter in der Übersetzung nach der gängigen Orthografie korrigiert, z. B. wurde bei Harrach, Ansichten 14 (S. 468) und 16 (S. 470) „mobilirt“ mit „meublé“ übersetzt.
Die lateinischen Inschriften wurden in den französischen Übersetzungen genau so übertragen, wie sie in den deutschen Texten erscheinen (mit Zeilenumbrüchen, Ligaturen, Gedankenstrichen, Großbuchstaben, Großschreibung der ersten beiden Buchstaben eines Wortes, Sonderzeichen, Abständen usw.). Nur die unkorrekterweise zusammengeschriebenen Wörter wurden getrennt. Es war nicht möglich, die lateinischen (und die vereinzelten altgriechischen) Inschriften vollständig zu übersetzen; jedoch wird in manchen Fällen jeweils am Ende der betreffenden Inschrift eine Übersetzung in Form einer Anmerkung angeboten.
Bei den in den deutschen Ursprungstexten wiedergegebenen lateinischen Zitaten können Trennungsstriche am Zeilenende in Form zweier Kommata („) wiedergegeben sein. In der französischen Übersetzung wurden diese durch den heute üblichen Bindestrich ersetzt, z. B. bei Corfey, Ansicht 18 (S. 17 ): „felicibus annae con„“ wird zu „felicibus annae con-“ in der französischen Version.
Ergänzungen der Herausgeber*innen und Übersetzer*innen
Hinweise und Ergänzungen der Herausgeber*innen — etwa die Hinzufügungen von Titeln zur besseren Gliederung einer Seite oder von Bildunterschriften zur Kennzeichnung von Zeichnungen — werden sowohl in den deutschen wie auch in den französischen Textfassungen in eckigen Klammern [ ] angegeben.
Die Übersetzer*innen mussten hin und wieder Zusätze (ein Verb, eine Nominalgruppe, ein Pronomen oder eine Konjunktion usw.) einfügen, um einen Satz verständlicher zu machen. Diese Zusätze sind mittels der Zeichen < > kenntlich gemacht.
Autor*innen: Hendrik Ziegler und Alexandra Pioch
The Digital Edition described here was conceived and realized for the ARCHITRAVE (Art and Architecture in Paris and Versailles in Accounts by Baroque-Era German Travellers) project comprising the following four partner institutions:
- Philipps-Universität Marburg (UMR)
- Niedersächsische Staats- und Universitätsbibliothek Göttingen (SUB Göttingen)
- Centre de recherche du château de Versailles (CRCV)
- Centre allemand d’histoire de l’art Paris (DFK Paris)
ARCHITRAVE is a FRAL-2016 programme, financed by the Deutsche Forschungsgemeinschaft (DFG) and the Agence nationale de la recherche (ANR).
This document contains the ARCHITRAVE encoding guidelines based on XML and following the TEI P5 encoding guidelines. This digital edition is composed of six sources kept in German public archives and libraries: one printed document and five manuscripts. These are the only known original versions of the texts (the manuscript for the printed document is irretrievable). All texts were written predominantly in German from the Baroque era. The authors also often used French and Latin and at times, Italian, Dutch and Spanish. They analyse and appraise French art and architecture in the late seventeenth and the early eighteenth centuries.
The corpora is composed of letters (Sturm and Neumann), diaries (Harrach and Corfey) and prose (Knesebeck and Pitzler). Only the Knesebeck text is published in its entirety, while the other five texts have been published in part, with a focus on extracts concerning Paris and Versailles.
About this document
This document presents all the tags used in the ARCHITRAVE digital edition. It explains phenomena found in the six sources and why and how it was decided to encode them. It does not replace the official TEI Guidelines developed and maintained by the Text Encoding Initiative (TEI) consortium.
Basic encoding
The choice of TEI P5
The TEI P5 Guidelines can be considered a little light for handling some forms of writing, especially letters. However, it was decided to follow these guidelines in order to assure permanence and the possibility to exchange data. Therefore, no other referential or non-standard elements will be found here.
A single XML (Extensible Markup Language) document has been created for each manuscript and its translation. The three indexes — persons, places, works (also called “registers”) — have been created in three distinctive tables using Google Sheets and have been extracted via XQuery into three XML documents.
Encoding principles
The ARCHITRAVE digital edition uses XML (Extensible Markup Language). The XML language comprises rules and tags to structure data within a document, allowing the addition of personalised elements since it is linked to a schema, which defines its grammar.
Tag
A tag is a markup construct that begins with < and ends with >.
Example:
<placeName>Paris</placeName>
The opening tag <element>
must be followed by a closing tag </element>. Those tags respect the
strict rules of nesting. Example:
<div>
<placeName>Paris</placeName>
</div>
Another type of tag exists, which indicates a point in the text where
something happens such as the beginning of a line or page. This is an
empty element, meaning it is composed of only one part with the "/" as a
suffix and does not frame any text content. Example: <pb/>
Element, attribute and value
The tag is named “element”. Each element name is defined by the
standard, i.e. the TEI. It can contain several properties called
“attributes”, which are associated with a value. Each property is placed
inside the opening tag following this pattern: <element attribute="value" attribute="value">text</element>. Each attribute is
separated by a space. The attribute value is always between quotes.
The value of the attribute is written according to the following rules:
- If the value is only one word, the entire word is spelled in lower
case such as
<div type="text">. - If the value is composed of several words joined together, one must
apply the Lower Camel Case convention, which means that the first word
is spelled in lowercase while the first letter of the following word
is in uppercase and the rest in lowercase. For example:
<placeName type="city" subtype="passingBy">. - Where the value starts with a number, then the word uses only
lowercase, as in
<gap reason="illegible" extent="1word"/>.
Establishment of the texts
The following are the various steps of the Digital Edition:
- Digitization of the original documents (manuscript or printed work).
- Transcription of the original documents by the editorial team in a Word document, with anticipation of encoding. It was decided to transcribe manually rather than use an OCR because of the complexity of the writing and constant changes in typography, sometimes even within a word.
- Translation into French of the six texts.
- Reading and validation of the transcriptions/translations by the scientific team.
- Converting the Word documents into files following the XML-TEI format with the automatic encoding supplied by the unzip of the ".docx".
- Cleaning of the files with the XSLT stylesheet for conversion into TEI P5 within the Oxygen XML editor and through the use of regular expressions.
- Loading the files into TextGridLab: checking the first layer of encoding and proceeding with the different layers of encoding.
- Checking and validating of the encoding by the TEI expert in charge.
- Checking and validating of the encoded files by the technical team in Göttingen.
Encoding environment
The editions are encoded and published within the TextGrid environment developed by the University of Göttingen. Answering an increasing demand for digital and collective research features in the humanities, TextGrid has, since its start in 2006, established the infrastructure for a respective virtual research environment. In continuous exchange with the scientific community, TextGrid has developed a variety of tools and services available for free download in a stable version. Together with the TextGrid Repository, the virtual research environment TextGrid offers scholars in the humanities sustainable editing, storing and publishing of their data in a thoroughly tested and safe environment. For further information on TextGrid, see: "TextGrid: A Project and its History": https://textgrid.de/en/projekt.
TextGrid can embed the Oxygen XML Editor which is a complete XML development environment that includes all necessary tools for working with a wide range of XML standards and technologies.
Sources encoding
The TEI document is built on a mandatory structure composed of two main
parts: the metadata and the text. The former is contained in the
<teiHeader> and the latter is framed by the <text>. The
transcriptions and the translations themselves are contained in the
<body> element, which is structured thanks to a <div> element. The
<front> and the <back> have not been used in the project.
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Title</title>
</titleStmt>
<publicationStmt>
<p>Publication Information</p>
</publicationStmt>
<sourceDesc>
<p>Information about the source</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<body>
<div>Some text here.</div>
</body>
</text>
</TEI>
The teiHeader
Overview
Any text in TEI format is made up of a TEI header followed by the main text. The header contains information essential for identifying the document.
This header can consist of a few lines only: the electronic title, the electronic editor and a brief description of the original source. In our editions, this data is completed by information on the original source, describing the method for electronic editing. The largest number of details is required to spread and exchange the electronic files. Experience showed that the more detailed the header is, the more referenced the file is, meaning it can be used more effectively.
The basic header must have the following structure:
<teiHeader>
<fileDesc>
<titleStmt>
<title>...</title>
</titleStmt>
<publicationStmt>
<authority>...</authority>
</publicationStmt>
<sourceDesc>
<p>...</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<fileDesc> is a file description containing a full bibliographic
description of an electronic file, with the electronic title, including
the people responsible for its edition and publishing, and the
bibliographic description of the original work.
We added 2 further parts, which are:
<encodingDesc>for the relationship between the electronic text and the source.<profileDesc>for a description of non-bibliographic aspects of the text.
Bibliographic description of the file: <fileDesc>
The bibliographic description of the file begins with the electronic title and the identity of the persons responsible for its intellectual content. The source, from which the file was generated, then undergoes bibliographic description.
The element <titleStmt> (title statement) contains the following
aspects:
<title>refers to the electronic title of the work, decided by the editorial team.<funder>specifies the name of institutions and organisations responsible for the project funding.<respStmt>(statement of responsibility) gives the name of the head of the electronic collection, and of those in charge of the edition. This element is repeated for each responsibility.
The element <editionStmt> (edition statement) contains the following
editorial elements:
<edition>indicates the editor of the present electronic edition, adding the date and URL of the website thanks to the tags<date>and<ref>.
The element <extent> indicates the text’s physical size (number of
kilobytes of the file).
The element <publicationStmt> (publication statement) contains
information on organisations/institutions responsible for the
publishing.
-
<authority> indicates the name of organisations/institutions responsible for the electronic work. This element is repeated for each institution.This tag contains the following sub elements:
<address>indicates the organisation’s address.<ref>gives the URL of the institution’s website.
Example:
<authority>
<ref target="https://chateauversailles-recherche.fr/">Centre de recherche du château de Versailles</ref>
<address>
<addrLine>Grand Commun</addrLine>
<addrLine>1, rue de l’Indépendance américaine</addrLine>
<addrLine>RP 834</addrLine>
<addrLine>78008 Versailles Cedex</addrLine>
<addrLine>France</addrLine>
</address>
</authority>
<availability>describes the legal distribution restrictions (licence).
The <sourceDesc> (source description) element is a mandatory part of
the header: it registers all information on the original source. It
contains the element <msDesc> (manuscript description). Though it
originally concerns the description of manuscripts, we also used this
tag for Sturm, a printed book. This element is commonly used to describe
ancient printed books when a great number of characteristics match those
of the manuscripts.
<msDesc> contains:
<msIdentifier>(manuscript identifier) indicates where to find the source: conservation site, identifier, country and city.
Here is an example concerning the Neumann text:
<msIdentifier xml:id="Bausachen_335_I">
<country xml:lang="de">Deutschland</country>
<settlement xml:lang="de">Würzburg</settlement>
<institution xml:lang="de">Staatsarchiv Würzburg</institution>
<idno>Bausachen 335/I</idno>
</msIdentifier>
The element <idno> indicates the catalogue number of the work within
the collection of the conservation institution.
<msContents>(manuscript contents) describes the intellectual content of a text. This element contains<msItem>(manuscript item), which contains other elements such as the title<title>, the author<author>, the date of the document<docDate>as well as a descriptive note on the content<note>.
Example:
<msContents>
<msItem>
<title xml:lang="de">Briefe Balthasar Neumanns seiner Reise nach Frankreich 1723</title>
<author xml:id="Neumann" xml:lang="de">Johann Balthasar Neumann</author>
<docDate>
<date from="1723-01-11" to="1723-04-14">11. Januar bis 14. April 1723</date>
</docDate>
<note xml:lang="de">In den Briefen gibt Balthasar Neumann Rechenschaft von seiner Anreise über Mannheim,
Straßburg, Zabern, Lunéville und Nancy nach Paris.[...]</note>
</msItem>
</msContents>
This is slightly different for the Sturm text, the only printed text of
our corpus. Instead of the tag <msItem>, we use <biblStruct>
(structured bibliographic citation), which contains the sub-element
<monogr> (monographic level). The latter contains the bibliographic
elements <title>, <author>, and <imprint>, which itself contains
<pubPlace>, <publisher>, <date>. Finally, we find in
<biblStruct> a note on the document content followed by another on the
document history.
Example:
<biblStruct>
<monogr>
<author xml:id="Sturm" xml:lang="de">Leonhard Christoph Sturm</author>
<title xml:lang="de">Leonhard Christoph Sturms Durch einen grossen Theil von
Teutschland und den Niederlanden biß nach Pariß gemachete Architectonische Reise-
Anmerckungen / Zu der Vollständigen Goldmannischen Bau-Kunst VIten Theil als ein
Anhang gethan / Damit So viel des Auctoris Vermögen stehet / nichts an der Vollständigkeit
des Wercks ermangle. Cum Gratia Privilegio Sacrae Caesareae Majestatis. Augspurg / In
Verlegung Jeremiae Wolffen, Kunsthändlers / Daselbst gedruckt bey Peter Detlefssen. Anno
M DC XIX.</title>
<imprint>
<pubPlace>Augsburg</pubPlace>
<publisher xml:id="Wolffen">J. Wolffen</publisher>
<date when="1719">1719</date>
<note xml:lang="de">Es handelt sich um ein Buch im Folio-Format mit einer
durchschnittlichen Blattgröße von 33 x 20 cm. Es umfasst 144 in Frakturschrift gedruckte
Textseiten und 52 teilweise aufklappbare Kupferstichtafeln (nummeriert von A bis D vor dem
Textteil und von I bis XLVIII im Anschluss an den Textteil).[...]</note>
<note type="history">Die schließlich 1719 publizierten Architectonischen Reise-
Anmerckungen sind aus der Kompilation unterschiedlicher Reisenotizen und Zeichnungen entstanden:[...]</note>
</imprint>
</monogr>
</biblStruct>
Concerning the manuscripts, a certain number of sub elements is used:
<physDesc>(physical description) contains the physical description of the source thanks to two main elements:<objectDesc>, contains the elements:<supportDesc>(support description) groups elements describing the physical support for the written part of a manuscript.<foliation>for a detailed description of the pagination.
<handDesc>contains as many<handNote>as there are hands to describe.
<history>, for a basic description of the document history in a<p>element, with potential tags<origDate>to indicate the date of the first known version and<origPlace>the place where it was originally written.
Example:
<physDesc>
<objectDesc>
<supportDesc>
<foliation corresp="#Neumann">
<p xml:lang="de">Die Foliozählung des Archivs ist meist unten mittig auf der Vorderseite eines jeden
Blattes aufgestempelt</p>
</foliation>
</supportDesc>
</objectDesc>
<handDesc>
<handNote corresp="#Neumann" medium="blackInk" scope="major" scribe="author">
<p xml:lang="de">Neumann verwendete zwei unterschiedlich große Briefbögen.[...]</p>
</handNote>
<handNote medium="blackInk" scope="minor" scribe="archivist" xml:id="Archivist"/>
</handDesc>
</physDesc>
<history>
<p xml:lang="de">Von der kunsthistorischen Forschung sind die Briefe Balthasar Neumanns seiner Reise nach
<origPlace>Frankreich</origPlace>
<origDate when="1723">1723</origDate> seit Langem als aussagekräftige Quelle erkannt
und herangezogen worden (s. Keller 1896).[...]
</p>
</history>
Encoding description: <encodingDesc>
The encoding description clarifies the methods and main editorial principles, which facilitated the text transcription and the file creation.
- The element
<projectDesc>(project description) contains a short description of the electronic project in a tag<p>. - The element
<samplingDecl>(sampling declaration) contains a description of the reasoning and methods used for text sampling within our corpus in a tag<p>. - The element
<editorialDecl>(editorial declaration) contains the encoding editorial practice in a tag<p>.
Non-bibliographic description: <profileDesc> (text-profile description)
This part contains non-bibliographic information to describe a document.
We only use the element <langUsage> to specify the language or
languages used. It is combined with the element <language>: the
identification is revealed by the attribute @ident with the language
code. The standard code classification corresponds to the ISO
639 codes.
Example:
<profileDesc>
<langUsage>
<language ident="de">German</language>
<language ident="la">Latin</language>
<language ident="fr">French</language>
<language ident="it">Italian</language>
<language ident="nl">Dutch</language>
<language ident="es">Spanish</language>
</langUsage>
</profileDesc>
The body
The element <text> is a mandatory container for the textual content.
It bears a mandatory @xml:lang attribute whose value is "de" for the
German texts and "fr" for the French translations, in agreement with the
IEFT BCP 47 and
compliant with the ISO 639
standard.
Example:
<text xml:lang="de">
Or
<text xml:lang="fr">
It is followed by <body>, which is the only sub-element of <text>.
The <body> contains the sub-elements <div> where the different text
levels are transcribed. In some cases, there is only one sub-element
<div> with an attribute @type whose value is text; in other cases
there are several <div> elements with different attribute @type
values, depending on the text structure.
Here is an example from Neumann with several <div>:
<div type="letter">...</div>
For the manuscripts comprising letters or the diaries with specific
entries: another level of division is used, with the tag <div>. It can
be typed with only two values.
Values for @type:
- diaryEntry
- letter
For the letters and diaries, a @when attribute is used to give the date
of the entries in ISO 8601
format: yyyy-mm-dd.
Here is an example from Harrach to explain a diary case:
<text xml:lang="de">
<body>
<div type="text">
<div type="diaryEntry" when="1698-10-23">
<p>...text...</p>
</div>
</div>
</body>
</text>
It is possible to give a title to a text division when appropriate. In
this case, <head> can be used. However, it can only be at the very
beginning of the division and only once. <p> and <label> are used to
encode the smaller divisions within the texts.
<div type="text">
<head rend="center">
<lb/>
<hi rend="latin">Paris den
<date when="1685-07-14">4/14 July 1685</date>.
</hi>
</head>
text
</div>
Elements common to all the manuscripts
Paragraphs: <p>
Entities to identify paragraphs.
Sub-titles within paragraphs are tagged as <label>:
<p>
<lb/>
<label>
<rs ref="wrk:textgrid:3pfbd" type="artwork">
<hi rend="latin">Henrici IV. Statua Equestris</hi>
</rs>.
</label>...some text...
</p>
<p>
<lb/>
<label>Der
<placeName ref="plc:textgrid:3pfmk" type="place">Kirche
<hi rend="latin">des grands Jesuites</hi>
</placeName>
</label>
</p>
Anonymous block: <ab>
For Corfey and Neumann, where paragraphs are missing, an arbitrary
division was made thanks to <ab>. It can have two values for the
attribute @type:
- day
- theme
When the author gives a date, we use it to structure the text. In such
cases, the @type used is "day". When no date is given, the @type "theme"
can be used to identify a part of the text.
<ab type="day"><date when="1698-06-21">den 21 iunÿ</date> seint wir...</ab>
<ab type="theme"><lb/>Nach dem <placeName type="place" ref="plc:textgrid:3pfpn">pont Royal</placeName> ist...</ab>
Line beginning: <lb/>
To mark the beginning of a new line, every <lb/> is placed at the
start of a line with no space after the tag and before the following
word. It is used inside the structural tags <p> or <div>:
<p>
<lb/>
<placeName type="city" ref="plc:textgrid:3pg0g">Paris</placeName> ist des ganzen Königreichs...
</p>
Or
<div type="letter" n="13">
<head>
<lb/>
<hi rend="latin">XIII.</hi>
</head>
<opener>
<salute>
<lb/>Mein Herr!
</salute>
</opener>
<p>
<lb/>OB mir wohl nicht unbekant ist, ...some text...
</p>
</div>
How to deal with the hyphenation thanks to the line beginning tag (</lb>)
In order to be able to search inside the text, the terms broken between
two lines have been marked. They are identified thanks to an attribute
inside the tag <lb/> splitting the word. This always contains the
attribute @break with the value "no" and the attribute @type to indicate
the way the hyphen is written by the author.
Values for @type:
- none
- doubleHyphen
- singleHyphen
Example Knesebeck view 25:

<lb/>Dÿck</hi></persName>, <persName ref="psn:textgrid:3q1kj" type="historical"><hi rend="latin">Hondhost</hi></persName>,
<persName ref="psn:textgrid:3pgdq" type="historical"><hi rend="latin">Rubens</hi></persName> und
<persName ref="psn:textgrid:3q1jn" type="historical"><hi rend="latin">Jor-
<lb break="no" type="singleHyphen"/>dan</hi></persName>, und mit vielen Golde her,,
Page beginning, form works and facsimiles: <pb/> and <fw/>
<pb/> appears at the start of each page with the attribute @n
indicating the value of the page. The pagination of several of the
sources was quite difficult. There are pages with the same number, some
missing pages or pages with a number that was later added by the author.
Since we could not work with pages bearing the same number as we were
using these numbers for the navigation system, we decided to create a
new pagination, although this interrupts the integrity of the work. The
value of the attribute @n is a continuous numbering. It is coupled with
an automatically added URI for each facsimile picture, contained in the
attribute @facs.
The form work tag (<fw>) is also used also for page numbers to
differentiate between multiple hands and the location on the page thanks
to the @place. The @hand is used to identify the person who has written
the number, for example the author or the archivist. This person is
referenced in the teiHeader by an @xml:id (first and last name initials)
in order to be linked to its occurrences in the text via the #
contained in the @resp. The added part of the page number has to be
encoded with the element <supplied>. The attribute @resp references
every page number created by a member of the team with this element
where none is given in the manuscript, and to justify the identification
of the hand. We also added an attribute @cert to clarify our position in
this regard.
Values for @place:
- topLeft
- topRight
- topCenter
- botLeft
- botRight
- botCenter
- leftCenter
- none
Example Knesebeck view 9:
<pb n="009" resp="#Architrave"/>
<fw type="pageNum" place="topRight" resp="#Knesebeck?">3
<supplied cert="high" reason="regularized" resp="#AJ">r</supplied>
</fw>
<fw type="pageNum" place="botCenter" resp="#archivist?">3
<supplied cert="high" reason="regularized" resp="#AJ">r</supplied>
</fw>

The sources were not encoded in their entirety. A selection was made to focus mainly on the itineraries through France. Therefore, the pagination is not always consistent. Moreover, the pagination of the original sources is also not always consistent. In some cases, we were not always able to determine whether a page was missing or if it even existed. Thus we did not encode missing pages, only the pages for which we have the digital pictures. For more information on the selection of the passages we chose to edit, please consult the introductive texts to each edition by clicking on "Edition / Édition" > "Quellenkorpus / Corpus des sources" and choosing the respective author. You will find detailed information under the section entitled "Zur Quelle / La source".
Paragraphs spanning several pages
Paragraphs spanning several pages are divided for ease of viewing. This
is done using the attributes @xml:id, @prev and @next. Each paragraph is
therefore assigned an xml:id. This is carried out as follows: p1. The p
refers to paragraph and the number to its rank. When a paragraph spans
several pages, the @xml:id is p1 with a letter suffix: p1a, p1b and p1c.
<p xml:id="p30a" next="#p30b">
<p xml:id="p30b" prev="#p30a" next="#p30c">
<p xml:id="p30c" prev="#p30b" next="#p30d">
<p xml:id="p30d" prev="#p30c">
Graphic divisions of the text: <metamark/>
The authors of the sources sometimes used lines to mark the distinction
between two divisions of text, however these lines do not belong to the
textual division. The choice between
<milestone>
and
<metamark>
was somehow a difficult one. Digital edition projects mostly use the
first tag. However, even if the drawn lines show an obvious intent to
divide the text, they are also used to underline a missing word, which
the author intended to fill in later or to help organise the layout of
the page. Since the textual divisions were already outlined, we decided
to use a rather graphical tag to encode those phenomena. We should also
add that the mandatory attribute @unit for the <milestone>, implying a
rather strong meaning of textual division, was not used, as we do not
wish to emphasise this aspect as regards the drawn lines present in our
sources.
<metamark> is used with the attribute @rend, whose values are:
- verticalLine
- horizontalLine
- dotedLine
- doubleHorizontalLine
- horizontal
Example Corfey view 15:
<lb/>
<quote xml:id="q36" xml:lang="la">
<hi rend="latin">genua emendata MDCLXXXIV</hi>
</quote>.
<metamark rend="horizontalLine"/>

Example Pitzler view 10:
<figure>
<figDesc>[Ansichten von Kaminen]</figDesc>
<figDesc>[Detailskizze von einem Kamin]</figDesc>
<p>
<hi rend="latin">profil</hi>
</p>
</figure>
<metamark rend="verticalLine"/>
Example Pitzler view 10:
<figure>
<p>
<lb/>So in einem Zimmer der Fußboden
<lb/>von Holz, kan vor dem
<hi rend="latin">camin</hi>
<lb/>eine steinerne Plate gelegt werden
<lb/>auch nach gelegeheit zierlich seùen
</p>
<figDesc>[Grundrisse/Skizzen von zwei Kaminen]</figDesc>
<p>
<lb/>
<hi rend="latin">camin</hi>
</p>
</figure>
<lb/>
<metamark rend="horizontalLine"/>

Sometimes the authors draw short lines along the text, to finish a line and create a separation before a quotation or at the end of a quotation for example. We used the character: _
Example Corfey view 16:
<lb/>
<quote xml:id="q39" xml:lang="la">
<hi rend="latin">
<foreign xml:lang="fr">du regne de Lovis XIV _ de la prevôté de Messire _ alexandre
<lb/>de Sueve _ prevôt des Marchands etc _ Ce present pont
<lb/>a été bâti
</foreign> _ aediles recreant Submersum flumine
<hi rend="below">pontem</hi> _
</hi>
</quote>

A hyphen is also used in some cases by authors in a poem or in an inscription to mark the end of a verse.
To transcribe double dashes, we used the = special character.
Example Corfey view 17:
<hi rend="latin">quod trajectum ad Mosam _ XIII diebus coepit = praefectus
<lb/>et aediles _ poni c c _ anno domini MDCLXXIII
</hi>

Changes in the manuscript: <del> and <add>
Five of the six sources are manuscripts in which we find deletions and
additions. Where someone other than the author has carried out a
deletion or addition, this is specified by the use of the attribute
@hand. The person is added inside the <handNote> and is also
referenced in the <teiHeader>.
Example Harrach view 13:
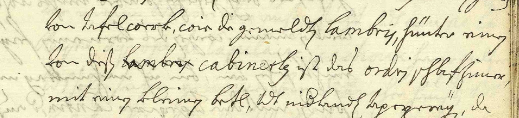
<lb/>von disen
<del hand="#Harrach" rend="strikethrough">
<hi rend="latin">lambris</hi>
</del>
<hi rend="latin">cabinetlen</hi> ist das
<hi rend="latin">ordry</hi> schlafzimer,
Values for @rend:
- strikethrough
- overwritten
The addition also has the @hand attribute denoting the deletion and a
@place attribute.
Values for @place:
- above
- below
- bottom
- top
- inline
- across
- marginLeft
- marginRight
- marginTop
- marginBottom
- nextPage
- prevPage
The <add> tag is used for all additions made with a clear sign or
anchor in the text and inside the layout of the page. Additions, which
do not follow these rules, are encoded with the <note> tag. See below
for more information on notes.
Example Knesebeck view 39:
<lb/>des
<persName ref="psn:textgrid:3q1jz" type="historical">königs Lud: XII.</persName>
<add place="above" xml:id="addp79_1a">
<hi rend="superscript">+)</hi>
</add> auffgerichteten
<hi rend="latin">Arcaden</hi>
[...]
<add place="bottom" hand="#Knesebeck"> +) und Anne de Bretagne</add>

Where the text of the addition and the sign or anchor are on two different pages, a link is made between the two.
Example Corfey views 5 and 6:
On one side, we have:
<pb n="5"/>
<add hand="#Corfey" place="nextPage" type="asterisk" xml:id="addab10_1a">
<ref target="#addab10_1b">
<hi rend="superscript">x</hi>
</ref>
</add>

On the other side:
<pb n="6"/>
[...]
<add hand="#Corfey" place="prevPage" type="asterisk" xml:id="addab10_1b">
<lb/><ref target="#addab10_1a"><hi rend="center">x</hi></ref>sonsten ist zu <placeName type="city">brussel</placeName>
noch Remarquir<add>en</add>s
<lb/>wert daß die hunde alda nicht allein
<lb/>vor die chaisen der Kinder, sondern
<lb/>so gahr <del rend="strikethrough" hand="Corfey">fur</del> vor absonderliche Karr<add>en</add>
<lb/>gespannet werden um getreit nach
<lb/>den Muhlen u<add>n</add>d gartengewachs nach
<lb/>der statt zu fuhren, u<add>n</add>d ist zu ver
<lb/>wundern das 4 hunde zuweilen Mehr
<lb/>als 1 pferd ziehen konnen
</add>

If a passage is blackened rather than struck through, making the text
illegible, it was encoded with a <del> combined with <gap>,
<unclear> or <supplied>.
Example Corfey view 135:
<lb/>con prb eccle Massiliens
<del hand="#Corfey" rend="strikethrough">
<gap cert="high" extent="1word" reason="illegible" resp="#AJ"/>
</del>
<lb/>anno XV eptus Sui d. ann VIII id OCB

The <subst> tag comprises a <del> and an <add> when they are
associated. In this case, the attribute @hand is placed on the <subst>
tag rather than on the <del> or the <add>, such as in the example
below.
Example Harrach view 12:
<subst hand="#Harrach">
<del rend="overwritten">freù</del>
<add place="across">donners</add>
</subst> tag den 3
<subst hand="#Harrach">
<del rend="overwritten">0</del>
<add place="across">1</add>
</subst>

Spaces inside the texts: <space>
Some blank spaces are significant inside the manuscript. They are
encoded with the tag <space>. The tag is associated with three
attributes: @extent, @dim (which allows only two values: "horizontal"
and "vertical") and @rend (with a value "blank" or "line"). The @extent
value varies according to the situation. For the @dim, we followed the
TEI Guidelines to specify irregular shapes. The value refers to the more
important of the two dimensions (horizontal or vertical). For left-right
scripts, the space is predominantly qualified as "vertical".
In general, we did not encode blank spaces in the French version.
Values for @dim:
- horizontal
- vertical
Values for @extent:
- 1word
- 2word
Values for @rend:
- blank
- line
A significant blank space can also be the result of a missing word or a
forgotten addition the author wanted to make later. For those cases, the
tag <space> is used too. The same attributes are used while adding the
@resp to distinguish the person in charge of identifying the significant
space. <space> and <gap> are distinct: the former is a blank space
found in the text as a deliberate gesture of the author, whereas the
latter refers to a part of the text that can not be transcribed.
Example Harrach view 55:
<space dim="horizontal" extent="1word" rend="blank" resp="#MM"/>
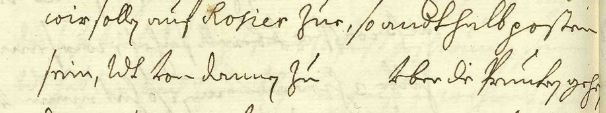
How to make a proposition: <supplied>
Proposals to fill a blank space have sometimes been made, thanks to the
<supplied> tag with the attributes @reason and @resp. An attribute
@cert was added where required. The supplied tag is also used in case of
damaged and unreadable extracts that one would like to interpret.
Values for @reason:
- illegible
- regularized
- translation
- unprinted
Example Sturm view 134:
<item>
<hi rend="latin">
<supplied cert="high" reason="illegible" resp="#MM">b.
<placeName ref="plc:textgrid:3r30x" type="place">Bosquet du Dauphin</placeName>
</supplied>
</hi>
</item>

Difficulties in reading: <unclear> and <gap/>
When a word is illegible, the tags <unclear> or <gap> were used.
<unclear> is used when the extracts are difficult to read or to
transcribe with certainty. It is associated with the attributes @reason,
@resp and @cert.
Values for @reason:
- illegible
Values for @cert:
- unknown
- low
- medium
- high
Example Harrach view 12:
<unclear cert="unknown" reason="illegible" resp="#MM">hans</unclear>
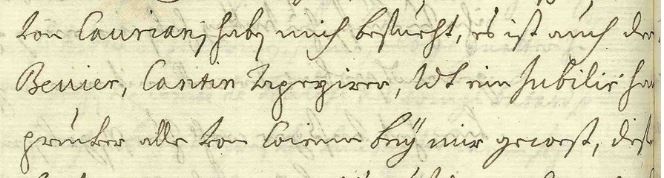
We use the tag <gap> for illegible passages for which an
interpretation is impossible. It takes the attribute @extent to give an
appreciation of the length, as <gap> is an empty tag, since it is
incapable of giving a clear idea of its impact on the text, unlike the
tag <unclear>. It is also working with the attribute @reason with the
same possible values as for <unclear>.
Values for @reason:
- illegible
Values for @extent:
- 1word
- 2words
Example Corfey view 77:

— 1
<del hand="#Corfey" rend="strikethrough">
<gap cert="high" extent="1word" reason="illegible" resp="#FD"/>
</del> biß 1
<num rend="horizontal" type="fraction" value="0.5">1/2</num> fues.
Example Corfey view 163:
<lb/>Benefactori
<unclear cert="unknown" reason="illegible" resp="#FD">anp</unclear> amplissimo

Example Corfey view 155:
<lb/>Veladus Maximï
<del hand="#Corfey" rend="strikethrough">
<gap cert="high" extent="1word" reason="illegible" resp="#AJ"/>
</del> filij

Example Corfey view 115:
<space dim="horizontal" extent="2words" rend="blank"/> VOLKANO

Sometimes the editor proposes an interpretation of an illegible word. In
this case, the <gap> tag is replaced by the <supplied> tag when the
text is completely illegible or missing. It is associated with the same
attributes @reason, @resp and @cert as for the <unclear> tag. If the
text is difficult to read but still legible, we used the <unclear>
tag.
Shift of hand: <hi> and @hand
The TEI Guidelines allow qualifying changes of hands inside the text
with the help of the tag <handShift> or with the attribute @hand. We
chose to encode the change of hand through the @hand attribute on
<subst>, <del> and <add> tags. When this was not possible, we
added a <hi> tag.
The different hands encountered in the manuscripts are: the authors, secretary, archivist.
For example, in Knesebeck’s manuscript a sentence had been filled in later using a pencil.
Values for @rend:
- pencil
- ink
- pencil_retraced_in_ink
Example Knesebeck view 144:
<hi rend="pencil">Hinter derselben ist der
<rs ref="wrk:textgrid:3q7gp" type="artwork">Todt Mariæ</rs>
</hi>

Example Neumann view 8:
<note type="secretary">
<lb/>
<hi hand="#Secretary" rend="ink">
<date when="1723-01-17">17
<choice>
<abbr>Jan:</abbr>
<expan>Januar</expan>
</choice> 1723
</date>
</hi>
</note>

Spelling corrections: <supplied>
We did not normalise the historical spelling or the missing glyphs.
However, we did make corrections when necessary in order to understand a
word thanks to the <supplied> tag, always using @resp and @cert
attributes.
Example Harrach view 2:
auß we
<supplied cert="high" reason="regularized" resp="#MM">c</supplied>hslung der münz, u
<supplied cert="high" reason="regularized" resp="#MM">n</supplied>dt andern nit
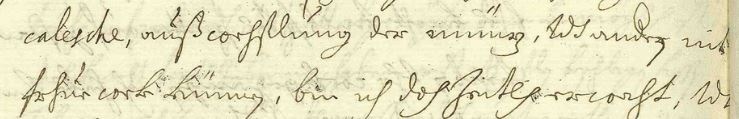
Agglutinated words and spaces between words
We did not use the <supplied> tag for the regulation of spaces since
this tag is employed for an addition made by the editor. We chose a
rather simple encoding: each term of the author’s expression is divided
and encoded with a <w> tag, which means, “word”. The first one bears
the attribute @type with the value "noSpace" and @n, which contains the
initial expression without the added spaces. We also used @join, which
can be "left", "right" or both (for the middle word when 3 words are
agglutinated) to indicate how the word is linked with the other part of
the expression. We decided not to use the @resp and @cert attributes in
this case in order to make the code easier for the encoders to read.
Example :
<lb/>lenderen
<w join="right" n="zuthuen" type="noSpace">zu</w>
<w join="left">thuen</w>

Use of special characters
For the special characters in our texts, we use unicode symbols. Here is the list of these characters:
- ⨀ (U+2A00) for the gilt colour symbol
- ☽ (U+263D) for the silvery colour symbol
- ⸗ (U+2E17) for the double hyphen symbol
- ☧ (U+2627) for the Christ monogram
- ⊕ (U+2295) used by Pitzler to mention a paging
- " (U+2033) for the double prime
- ̊ (U+030A) for a diacritic sign in Harrach
Abbreviations: <choice>, <abbr> and <expan>
We decided to develop every abbreviation contained in the texts. If the abbreviation has a French or Latin origin, it will be expanded in German. For this reason, oct. is expanded to "October" and not "octobre" or "octobris".
Example Harrach view 2:
<date when="1698-10-20">Montag, den 20
<hi rend="latin">
<choice cert="high" resp="#FD">
<abbr>Oct</abbr>
<expan>October</expan>
</choice>
</hi>
</date>
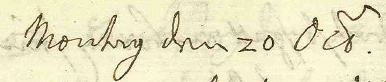
However, the words finishing with “-en” are not considered abbreviations. This issue stems from an unclear writing. They have not been encoded but simply transcribed in full, in order to lighten the encoding.
Foreign language: <foreign>
The two main languages are French and German: they are specified in the
<profilDesc> of the teiHeader as well as the value attribute at the
root tag <text> (example: <text xml:lang="de">). To highlight parts
of the text written in a language other than the two main languages, the
attribute xml:lang is used on <p>, <hi> and on <quote>. If the
change of language is independent of an existing tag, then the
<foreign> tag is used with the @xml:lang as attribute.
As defined by the TEI consortium, the xml:lang is a standard format. We decided to follow the ISO 639.
Values for @xml:lang:
- fr for French
- de for German
- it for Italian
- nl for Dutch
- es for Spanish
- la for Latin
- en for English
Quotations: <quote>
All the quotations and epigraphs are encoded with the <quote> tag. It
is the only encoding layer applied on this type of information.
The <quote> is often in another language: the attribute @xml:lang is
then specified. An attribute @rend on a <hi> tag is used to indicate
the quote’s position on the page.
Values for @rend:
- left
- right
- center
Example Corfey view 108:
<lb/>
<quote xml:id="q150" xml:lang="la">
<hi rend="latin">
<hi rend="center">VXORI
<lb/>OPTIMAE
<lb/>T. FLAVIVS
<lb/>AVG. LIB.
<lb/>ASIATICVS.
</hi>
</hi>
</quote>

Highlighted text: <hi>
According to the TEI Guidelines, the tag <hi> is used to embody a
graphical change between the tagged part of the text and its
surroundings, such as a graphical change in script. The attribute @rend
is associated with it.
Values for @rend:
- underline
- superscript
- latin (in opposition to a cursive script, default state of the text)
- italic (in order to follow the modern editorial convention for French texts)
- pencil
- left
- right
- center
- above
- below
- dotedLetter
- smallCaps
- ink
- pencil_retraced_in_ink
Example Corfey view 134:
<hi rend="dottedLetter">PLEBS</hi> narbonensis
<lb/>
<hi rend="dottedLetter">N</hi>uminis augusti di
<lb/>cavit
<unclear cert="unknown" reason="illegible" resp="#FD">
<hi rend="dottedLetter">ARAM</hi>
[...]
Example Knesebeck view 7:
<hi rend="latin">Von
<placeName n="1" ref="plc:textgrid:3pfv7" subtype="passingBy" type="city">Braunschweig</placeName> ist die erste Post nach
<placeName n="2" ref="plc:textgrid:3pxdb" subtype="passingBy" type="city">Peina</placeName>
</hi>

Example Sturm view 5:
<hi rend="latin">Excell.</hi> der Herr Graff von N. erwählet hat seinen Sohn,

Lists: <list> and <item>
It was decided to use a light structure to encode lists with only two
tags, <list> and <item>, and no attributes. The text contained
inside a <figure> tag can not be encoded as <list>. In the texts, a
list is characterised as short: each item comprises only a few lines.
Moreover, the layout is different from the rest of the text.
Example Sturm view 23:
<list xml:id="l1">
<item>Erstlich: Daß die drey Schlitze durchgehends an einem Gebäude gleiche
<lb/>weit voneinander stehen.
</item>
<item>Zweytens: Daß sie an der Höhe gegen der Breite sollen seyn wie drey gegen
<lb/>zwey.
</item>
<item>Drittens: Daß die Zwischen⸗Tieffe, das ist der ledige Platz, so zwischen
<lb/>zwey Drey⸗Schlitzen bleibet, ein
<hi rend="latin">accurat Quadrat</hi> sey.
</item>
<item>Vierdtens: Daß über die Mitte der Säule just die Mitte deß Drey⸗Schlitzes
<lb/>zutreffe.
</item>
<item>Fünfftens: Daß über den Fenstern Thüren und Bilder⸗Blindten, entweder
<lb/>ein Drey⸗Schlitz, oder eine zwischen Tieffe mit der Mitte <hi rend="latin">accurat</hi> zutreffe.
</item>
<item>Sechstens: Daß das gantze Gebälcke just vier <hi rend="latin">Modul</hi>, oder zwey Säulen⸗
<lb break="no" type="doubleHyphen"/>Dicken hoch sey, endlich
</item>
<item>Siebendens: Daß der Borten nicht niedriger seyn soll, als der <hi rend="latin">Arcchitrav</hi>.
</item>
</list>

If part of the list is located on the page, we use the attribute @rend
on a <cb/> tag (see below) with left, center or right. In cases where
only the number has its own layout, it is encoded with the <num> tag
and the attribute @rend.
Example Knesebeck view 26:
<list xml:id="l1">
<item><hi rend="latin">a.</hi> der Sahl der algemeinen <hi rend="latin">Conferentien.</hi></item>
<item><hi rend="latin">b.</hi> gemächer des <hi rend="latin">Mediatoris.</hi></item>
<item><hi rend="latin">c. deßen</hi> Gemach zu den besondern <hi rend="latin">con,,
<lb/>ferentzien.</hi></item>
<item><hi rend="latin">d.</hi> freùplätze vor der treppe,</item>
<cb rend="right"/>
<item><hi rend="latin">e. galerien.</hi></item>
<item><hi rend="latin">f.</hi> gemächer der <hi rend="latin">Alliirten</hi> Ab,,
<lb break="no" type="doubleHyphen"/>gesandten,</item>
<item><hi rend="latin">g.</hi> Gemächer der frantzösischen
<lb/>Abgesandten.</item>
</list>

Fractions: <num>
Numbers are not encoded in the texts. Nevertheless fractions are encoded
using a <num> tag with an attribute @type and @value. The @type has
just one value ("fraction"), while the @value is the fraction translated
into a numerical value.
Example:
<num type="fraction" value="0,5">1/2</num>
The tag <num> for fractions is associated with the @rend attribute
"horizontal".
Columns beginning: <cb/>
The tag marks the beginning of a new column on a page containing several
columns, and is associated with the @rend attribute.
Values for @rend:
- left
- center
- right
Example Corfey view 172:
<cb rend="left"/>
<quote next="#q279b" xml:id="q279a" xml:lang="la">
<hi rend="latin">
<lb/>Sex. aemilio paullo patri
<lb/>aemiliae q. F. Regiliae Mat.
<lb/>Sex aemil
<w join="right" n="paullinofratri" type="noSpace">paullino</w>
<w join="left">fratri</w>
<lb/>C. aemil. Vestus
<lb/>suis.
<lb/>
<metamark rend="horizontalline"/>
</hi>
</quote>
<cb rend="center"/>
<quote next="#q279c" prev="#q279a" xml:id="q279b"
xml:lang="la">
<hi rend="latin">
<lb/> T. Cornelio
<lb/> T. F. Nasoni
<lb/> Tertia uxor.
<lb/>
<metamark rend="horizontalline"/>
<lb/>Mercurio
<lb/>V. s.
<lb/>priscilla.
<lb/>
<metamark rend="horizontalline"/>
</hi>
</quote>
<cb rend="right"/>
<quote prev="#q279b" xml:id="q279c" xml:lang="la">
<hi rend="latin">
<lb/>A. Cornelio
<lb/>M. F. Cano
<lb/> Tertia uxor.
<lb/>
<metamark rend="horizontalline"/>
</hi>
</quote>

Tables: <table>
The table is composed of a main tag <table> divided in <row>, which
contains the tag <cell>. The table can have one tag <head> just
after the opening tag <table>. If a cell has a role of header for the
columns or the rows, we use the attribute @role with the value "label".
Value for @role:
- label
Example Corfey view 64:
<table>
<head>le Corps de bataille 2 ligne</head>
<row>
<cell role="label">2 bourbonnois</cell>
<cell>W</cell>
<cell>W</cell>
<cell>R</cell>
<cell>R</cell>
</row>
<row>
<cell role="label">1 la Couronne</cell>
<cell>W</cell>
<cell>bl</cell>
<cell>bl</cell>
<cell>bl</cell>
</row>
<row>
<cell role="label">2 Lionnois</cell>
<cell>W</cell>
<cell>R</cell>
<cell>gru</cell>
<cell>R</cell>
</row>
<row>
<cell role="label">1 La Chastre</cell>
<cell>W</cell>
<cell>R</cell>
<cell>ge</cell>
<cell>R</cell>
</row>
</table>
Dates: <date>
Dates are encoded to date letters and itineraries when day-month-year are given. They are not encoded when only the year is given, when associated with works of art or inside quotations and inscriptions cited in the texts.
Dates are encoded as <date>. They have been normalised following the
ISO 8601 standard. Their form
is year-month-day given as value of the attribute @when. It always uses
the Gregorian calendar as reference.
Example:
<date when="1698-10-20">Montag, den 20 Oct</date>
Named entities such as persons, places and artworks: <persName>, <placeName>, <geogName> and <rs>
Name entities are not encoded when the names of places, people and works are quoted in citations or inscriptions in Latin or other languages.
The are sometimes differences between the German version (transcription)
and the French version (translation): adjectives in German are sometimes
transformed into nouns in French. For example in Harrach view 48, we
have encoded the countries "France" and "Denmark" in the French version,
but not in the German transcription since they are adjectives ("die
beede in franzosischen diensten sein" ; in French: "tous deux en mission
en" `
Persons
Every time a person, a place, a geographical feature or a work of art is
evoked, it has be encoded with <persName>, <placeName>, <geogName>
and <rs> respectively. For each one, an entry is created in an index
and receives a unique TextGridID. This reference is given as the
attribute’s value thanks to the @ref. It is built with a prefixe: "psn"
for persons, "wrk" for artworks and "plc" for places and geographical
features.
The <persName> is also associated with an attribute @type whose value
is unique: "historical". This reflects the evolution of the encoding
choices: at the beginning of the project, the tag <persName> bore
three types: "historical", "mythological" and "religious". It was later
decided to leave out the mythological and religious persons.
Example:
<persName ref="psn:textgrid:3q1jk" type="historical">duc d’Albe</persName>
The names are typed and when required, subtyped.
Value for @type:
- historical
Values for @subType:
- family
- persons: used inside a
<persName>tag to encode several persons
Examples:
- Harrach view 11:
<persName ref="psn:textgrid:3q1tw psn:textgrid:3q1tv" subtype="persons" type="historical">2 söhn</persName>
- Neumann view 91:
beù denen <persName ref="psn:textgrid:3pg7t psn:textgrid:3qwc0" subtype="persons"
type="historical"><hi rend="latin">Architectis</hi></persName>
- Neumann view 74: when a person could not be clearly identified but the editor made 2 or more propositions of identification, we used the subType "persons" and encoded several persons :
ein <hi rend="latin"><persName ref="psn:textgrid:3qwc5 psn:textgrid:3qwc8 psn:textgrid:3qwcb"
type="historical" subtype="persons">tapecier</persName>
Geographical names
The geographical features are typed.
Values for @type:
- mountain
- water
- desert
- island
Places
The places are typed and when required, subtyped.
Values for @type:
- continent
- country
- region
- district
- city
- place
Values for @subType:
- passingBy
- rooms: used to encode several rooms of a residence inside a same
<placeName>tag - residences: used to encode several residences inside a same
<placeName>tag
Examples:
<placeName ref="plc:textgrid:3ph2b" type="city" subtype="passingBy" when="1698-10-24"><hi rend="latin">Poitiers</hi></placeName>
<placeName ref="plc:textgrid:3pfsf plc:textgrid:3pfsj" subtype="rooms" type="place">2 vierekten gleichen Saalen</placeName>
<placeName ref="plc:textgrid:3pfdg plc:textgrid:3pfdn plc:textgrid:3pfdk plc:textgrid:3pfdc" subtype="residences"
type="place">vier Königlichen Pallästen</placeName>
A complementary layer of encoding has been added for some places: if a
traveller went through or visited a place, it is specified thanks to the
attribute @subtype whose value is "passingBy". An attribute @n indicates
the order of the cities passed through all along the route. If possible,
it can be associated with the attribute @when with the date of the day
in ISO 8601 format the
traveller was there. This encoding is used to visualize the itineraries
of the travellers on maps of Europe, France and Paris (see the section
Reiserverlaüfe
/ Itinéraires des
voyageurs).
However, it was decided to avoid mentioning the fictional descriptions
of places never visited.
Examples:
<placeName ref="plc:textgrid:3pfvv" type="city" subtype="passingBy" n="1" when="1698-06-18">Warendorff</placeName>
<placeName ref="plc:textgrid:3pfvk" type="city" subtype="passingBy" n="2" >Munster</placeName>
<placeName ref="plc:textgrid:3pfv9" type="city" subtype="passingBy" n="3" when="1698-06-19">Coesfeld</placeName>
We have encoded:
- 24 passingBy in Pitzler
- 46 passingBy in Harrach
- 120 passingBy in Corfey
- 67 passingBy in Knesebeck
- 48 passingBy in Neumann
Works
The <rs> is also associated with an attribute @type whose value is
unique: artwork. This reflects the evolution of the encoding choices: at
the beginning of the project, the tag <rs> bore three types:
"artwork", "book" and "technic". It was later decided to use one single
sub-type for all types of artworks (paintings, sculptures, drawings,
tapestries, engravings, books, machines and other technical devices...).
Value for @type:
- artwork
Examples:
<rs ref="wrk:textgrid:3pfbf" type="artwork"><hi rend="latin">statua</hi></rs>
Named entities across two pages
When entities span two pages, the encoding has to be adapted to simplify
viewing. The system is the same as for <p> tags. In addition to the
attributes @type and @ref, each part of the entity is encoded with an
@xml:id built with the TextGridID + "-a" for the former and "-b" for the
latter. The attributes @next for the first half and @prev for the other
half are added to point to the id of the other part.
Example Corfey views 91-92:
91:
<persName next="#textgrid3pgg2-b" ref="psn:textgrid:3pgg2" type="historical" xml:id="textgrid3pgg2-a">Madame</persName>`

92:
<ab next="#ab111c" prev="#ab111a" type="theme" xml:id="ab111b"><lb/><persName prev="#textgrid3pgg2-a" ref="psn:textgrid:3pgg2"
type="historical" xml:id="textgrid3pgg2-b">la duchesse de Bourgogne</persName>
Notes
There are two types of notes in the ARCHITRAVE digital edition.
- The ones contained in the original sources, which can have been
written by the author, the archivist or the publisher. They are
close to the
<add>tag, which is why the attributes@placeand@handare also used. They are typed "authorial".
Values for @type:
- authorial
- archivist
- editorial
- translation
- scientific
- secretary
Values for @place:
- marginLeft
- marginRight
- marginTop
- marginBottom
Example Corfey view 2:
<note place="marginLeft" type="authorial">Wilmstat.</note>

Among the project’s sources, Sturm is an exception since it is a printed source for which we can not evaluate the role of the author and the role of the editor/publisher. That is why the annotations have been typed "editorial".
Example Sturm view 80:
<note place="marginLeft" type="editorial"><hi rend="latin">Clagny</hi>.</note>

The second group of notes does not appear in the sources: they are the
notes provided by the ARCHITRAVE team. These annotations are typed and
linked to the contributor with an attribute @resp.
Values for @type:
- translation (notes made by the translators)
- scientific (annotations by the editorial team related to the edition of the manuscripts)
Example Harrach view 2:
- German version:
<note type="scientific" resp="#HZ">Harrach meint wahrscheinlich die bereits in Frankreich liegende Gemeinde
„Urrugne“, die zwischen Irun und St.-Jean-de-Luz liegt.</note>
- French version:
<note type="scientific" resp="#HZ">Harrach désigne par « Ordonno » en allemand probablement
« Urrugne », commune française située entre Irun et Saint-Jean-de-Luz.</note>
Stamps: <stamp>
The marks and wording from the stamps are marked up with the element
<stamp>.
Example Knesebeck view 3:
<stamp>
<lb/>Ex
<lb/>Bibliotheca
<lb/>Academiae
<lb/>Rostochiensis
</stamp>
Drawings: <figure> and <figDesc>
To represent any graphic element, the TEI uses the tag <figure>. A
description of the drawing written by one member of our team is
contained in the tag <figDesc>. And the author’s comment is toggled
between <p>. A named entity contained in a <figDesc> is encoded only
if the person, place or work is not mentioned previously on the page.
Example Pitzler view 3:
<figure>
<p>
<lb/>Anmerckung
<lb/>wo ein austrit wie beù <hi rend="latin">A</hi>
<lb/>gemacht werden soll, konnen
<lb/>die <hi rend="latin">sopports</hi> uf diese arten seyn
</p>
<figDesc>[Detailskizzen von Konsolsteinen]</figDesc>
</figure>
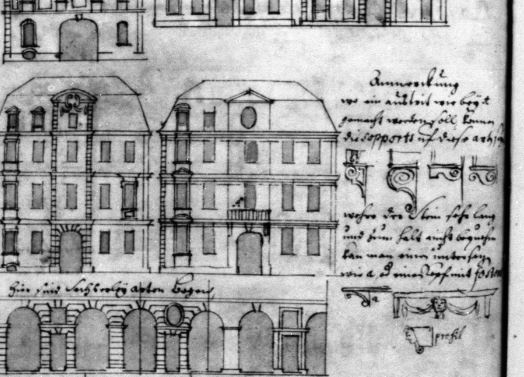
Pointers and links inside one manuscript: <ref>
Different locations inside one manuscript can be interlinked together
thanks to the tag <ref>, associated with an attribute @target, wich
points to an attribute @xml:id. The pointers are used to link a mention
of a drawing or plate and the drawing or engraving itself, mostly when
the latter is to be found at the end or at the beginning of the text. We
have created @xml:ids to set up the links.
Example:
- Knesebeck view 69:
<ref target="#knesebeck_fig.2" xml:id="knesebeck_drawing_2">grundriß zu sehen</ref>
is linked to:
- Knesebeck view 152:
<figDesc xml:id="knesebeck_fig.2"><ref target="#knesebeck_drawing_2">[2] [Lageplan von dem Collège
des Quatre-Nations in Paris]</ref></figDesc>
Specific elements for encoding letters and diaries
Letters and diaries are encoded with a specific structure.
Opener: <opener>
The preliminary part of a letter is encoded with the <opener> tag. It
can comprise the <salute> tag for the salutations.
Example Neumann view 1:
<opener>
<lb/>
<salute>Hochwürdtigster Reichs fürst Gnädigster
<lb/>fürst vndt Herr Herr.
</salute>
</opener>

Closer: <closer>
For the complementary close of the letter, we use the <closer> tag,
which groups together salutations (<salute>), the place and the date
(<dateline>) and the signature (<signed>).
Example Sturm view 9:
<closer>
<lb/>
<salute>Meines Herrn</salute>
<lb/>
<dateline>
<address>
<lb/>
<addrLine>
<placeName ref="plc:textgrid:3q1d1" type="city">Rostock</placeName>
</addrLine>
</address>
<date when="1716-08-28">den
<hi rend="latin">28. August 1716.</hi>
</date>
</dateline>
<lb/>
<lb></lb>
<signed>
<hi rend="right">Unvermögender doch gutwilliger
<lb></lb>Diener
<lb/>
<hi rend="latin">N.N.</hi>
</hi>
</signed>
</closer>

Addresses: <address> et <addrLine>
The address tag is used to encode an address. It can be found in letters
and in diary entries. Each line is also encoded as <addrLine> inside
which it is possible to encode the places and persons as specified
above. <addrLine> means a new line of an address, so <lb/> is not
used at the same time.
Example:
<address>
<addrLine>
<placeName type="city">Rostock</placeName>
</addrLine>
</address>
The encoding of translations is very similar to that of German texts
except for some details. We decided not to keep the <lb/> tags. The
encoding of the text-formatting with the <hi> tag is also excluded.
Only foreign languages such as Latin are tagged with <hi>. For this
case, the value of @rend is "italic". All encoding relating to
specificities of the German source, such as for letters added to correct
original spellings, the encoding of abbreviations, unclear words for
which the translator made choices, is of course absent from the French
texts.
The translation does not follow the line breaks of the German transcription, which reproduces the layout of the original German text, but remains as close as possible to it for the rest of the layout: the sentence breaks from one page to the other, line breaks and blanks, indentation, presentation of lists and tables, legends of drawings and sketches, arrangement of Latin quotes and inscriptions, dashes, lines and horizontal lines. The underlining has been retained only occasionally to facilitate locating and to compare the French to the German text placed opposite. However, the distinct font used in some passages in cursive script in the German texts is not reproduced in the translation.
Index encoding
The ARCHITRAVE digital editions have three indexes, one for persons, one for places and one for works of art and architectural elements described by the authors. Enrichment of indexes was carried out in three Google Sheets, which have been transformed in three XML-TEI files.
For detailed information about the content of indexes, see index guidelines: Informations sur les index / Registerrichtlinien.
Index of persons
The XML-TEI file contains a simplified teiHeader with the edition and
publication information as for the XML-TEI files of the 12 editions. The
index is in the <body> tag inside <text>. It is organised in list
form inside the tag <listPerson>, which contains as many <person>
tags as we have different persons in our texts. The tag <person> is
typed with the two values "identified" or "unidentified". It uses an
@xml:id whose value is unique for each person and is composed of
“textgrid:” followed by a mix of five letters and numbers. This @xml:id
links each occurrence of the person in our texts to their record in the
index.
A <person> is denoted with two tags <persName> for its name in both
languages : German and French. The attribute @xml:lang is used to
specify the language in ISO 639
format ("de" for German and "fr" for French).
The link to an online repository is given in the <idno> tag. We
principally use VIAF (Virtual International
Authority File). Where the person does not exist in this repository, we
can link it to Wikidata,
dataBNF or Biblissima
for example.
The nationality is given with the element <nationality> in French and
German thanks the attribute @xml:lang.
There are several <occupation> tags with the attribute @type and the
value "category" to denote each occupation of the person during his or
her life. It is repeated as much as necessary.
Two elements "note" give more information about this person in both languages.
The birth and death dates and places are given in <birth> and
<death> tags inside a <date> and a <placeName> element.
Example:
<listPerson>
<person xml:id="textgrid:3pgcb" type="identified">
<idno xml:base="https://viaf.org/viaf/7399719" type="viaf"/>
<persName xml:lang="de">Montespan, Françoise-Athénaïs de Rochechouart de Mortemart, Marquise de</persName>
<persName xml:lang="fra">Montespan, Françoise-Athénaïs de Rochechouart de Mortemart, marquise de</persName>
<nationality xml:lang="fra">français</nationality>
<nationality xml:lang="de">französisch</nationality>
<occupation type="category" xml:lang="fra">favorite / maîtresse de Louis XIV</occupation>
<occupation type="category" xml:lang="de">Marquise seit 1663</occupation>
<occupation type="category" xml:lang="de">Mätresse Ludwigs XIV. seit
1667</occupation>
<note type="description" xml:lang="fra"><p>maîtresse de Louis XIV</p></note>
<note type="description" xml:lang="de"><p> Herrin von Ludwig XIV.
</p></note>
<birth>
<date xml:lang="de">1640-10-05 (1641 ?)</date>
<date xml:lang="fra">1640-10-05 (1641 ?)</date>
<placeName>Lussac-les-Châteaux (Frankreich / France) 1034148 ?
(Tonnay-Charente (Frankreich / France)</placeName>
</birth>
<death>
<date xml:lang="de">1707-05-27</date>
<date xml:lang="fra">1707-05-27</date>
<placeName xml:lang="fra">Bourbon-l'Archambault (Frankreich / France)</placeName>
</death>
</person>
</listPerson>
This structure is the same for each person.
Index of places
This index is built on the same model as the person index with the tags
<listPlace> and <place>. The tag <place> is typed with the two
values "identified" or "unidentified" and subtyped with one of the ten
following values: "military", "religious", "domestic", "interior",
"public", "garden", "monuments", "geographic", "infrastructure",
"other". It uses an @xml:id on the same model as the person tag.
A <place> comprises four tags <placeName> typed "current" or
"historical", each in both languages French and German with an
@xml:lang.
The link to an online repository is given in an <idno> tag. We
principally use Wikidata for places and in
few cases the Getty
TGN (Getty
Thesaurus of Geographic Names).
GPS coordinates are given inside the couple tags <location> and
<geo>.
There are several <note> tags with different types to describe a
place. Each one is duplicated for the French and the German versions.
The first one specifies whether the place has always existed, with the
attribute @type and the value "state". The second one determines the
function of the place with the attribute @type and the value "function".
The third gathers the artists working at the place at the end of the
17th century and the beginning of the 18th century. This note has
the attribute @type with the value "artist". Each person is encoded with
the <persName> tag and a link to VIAF is given where possible. Where
the artist is already mentioned in our texts, we give its TextGridID in
the attribute @ref inside the <persName> tag. The fourth note gives a
description of modifications of this place with the attribute @type and
the value "event". The last note is a description of the place with the
attribute @type and the value "description".
Example:
<listPlace>
<place xml:id="textgrid:3pff1" type="identified" subtype="domestic">
<idno xml:base="https://www.wikidata.org/wiki/Q3145712" type="wikidata"/>
<placeName type="historical" xml:lang="fra">hôtel d'Angoulême</placeName>
<placeName type="historical" xml:lang="de">Hôtel d'Angoulême</placeName>
<placeName type="current" xml:lang="fra">Paris, hôtel Lamoignon</placeName>
<placeName type="current" xml:lang="de">Paris, Hôtel Lamoignon</placeName>
<note type="state" xml:lang="fra">conservé</note>
<note type="state" xml:lang="de">erhalten</note>
<note type="function" xml:lang="fra">hôtel particulier</note>
<note type="function" xml:lang="de">Hôtel particulier</note>
<note type="artist">
<persName><Philibert de L'orme
(https://viaf.org/viaf/205549982)></persName>
<persName><Thibault Métezeau
(https://www.wikidata.org/wiki/Q3524037)></persName>
<persName><Jean Thiriot (https://viaf.org/viaf/247691052)></persName>
</note>
<note type="event" xml:lang="fra">1585: début des travaux; 1589: fin des
travaux; 1624-1640: modifications</note>
<note type="event" xml:lang="de">1585: Baubeginn; 1589: Bauende; 1624-1640:
Umbauphase</note>
<location>
<geo>48.85703199999999,2.361833299999944</geo>
</location>
<note type="description" xml:lang="fra">Construit en 1585-1589 puis repris en
1611, le premier état de l'hôtel de Lamoignon est attribué à Thibault
Métezeau. Il a été anciennement attribué à Philibert Delorme. Des
modifications sont réalisées entre 1624 et 1640 par les entrepreneurs
François Boullet et Jean Thiriot. [AJ]</note>
</place>
</listPlace>
This structure is the same for each place.
Index of works
The index of works is built on the same model but this time with one
element <item> per work included in an element <list>. The tag
<item> is typed with the two values "identified" or "unidentified" and
subtyped with the values "sculpture", "painting", "book", "engraving",
"others". It uses an @xml:id like for the <person> and <place>
names.
A first <note> tag with an attribute @type is used to give the name of
the artist of the work.
The name of the work is encoded in a <name> tag in both languages and
the date in a <date> tag.
The link to an online repository is given in an <idno> tag. We used
several reference and collections databases, including: Wikidata, the
Louvre collections, the Versailles collections, AGORHA, Gallica...
The location of the work is given in <location> and <placeName>.
Where this place has already been mentioned in our texts, we give its
TextGridID in an attribute @ref inside a <placeName> tag.
There are several <note> tags with different types to describe a work.
Each one is duplicated for the French and the German versions. The first
one specifies whether the work always existed or not, with the attribute
@type and the value "state". The second one specifies the material of
the work with the attribute @type and the value "material". The third
gives the dimensions with the attribute @type and the value
"dimensions". The last one is a description of the place with the
attribute @type and the value "description".
Example:
<item xml:id="textgrid:3pfbf" type="identified" subtype="sculpture">
<name type="painting" xml:lang="fra">Statue équestre de Louis XIII</name>
<name type="painting" xml:lang="de">Reiterstatue von Ludwig XIII.</name>
<note type="artist">
<persName ref="textgrid:3q1p0"><Da Volterra, Daniele
(textgrid:3q1p0)></persName>
<persName ref="textgrid:3pg5v"><Biard, Pierre le Jeune
(textgrid:3pg5v)></persName>
</note>
<date xml:lang="fra">1639</date>
<date xml:lang="de"/>
<note type="state" xml:lang="fra">détruite</note>
<note type="state" xml:lang="de">zerstört</note>
<location type="former">
<placeName ref="textgrid:3pfpc">Paris, Place des Vosges / Paris, place des
Vosges (textgrid:3pfpc)</placeName>
</location>
<note type="material" xml:lang="fra">bronze</note>
<note type="material" xml:lang="de">Bronze</note>
<note type="dimensions" xml:lang="de">366 cm</note>
<note type="dimensions" xml:lang="fra">366 cm</note>
<note type="description" xml:lang="fra"><p>L'ensemble fut détruit le 11
août 1792 et remplacé en 1829 par une statue équestre en marbre due à
Louis-Marie-Charles Dupaty et Jean-Pierre Cortot.</p></note>
<note type="description" xml:lang="de"><p>Das Ensemble wurde am 11. August
1792 zerstört und 1829 ersetzt durch ein marmornes Reiterdenkmal von
Louis-Marie-Charles Dupaty und Jean-Pierre Cortot.</p></note>
</item>
This structure is the same for each work.
Authors of the “Encoding guidelines”: Axelle Janiak, Mathieu Duboc
Copyediting: Alexandra Pioch, Emer Lettow
Current version published on 22 September 2021
Auf der Webseite ARCHITRAVE ist im Drop-down-Menü „Edition“ die Rubrik
„Register“ zu finden:
Diese gibt Zugang zu drei Registern, in denen weitestgehend alle in den
sechs edierten Texten erwähnten Personen, Orte und Werke aufgeführt
sind. Die drei Kategorien von Registereinträgen sind innerhalb der
Editionen jeweils durch unterschiedliche Symbole gekennzeichnet (siehe
das Popup-Menü „Information zur
Edition“ in der horizontalen Symbolleiste jeder Edition).
in der horizontalen Symbolleiste jeder Edition).

Zusätzlich zu den alphabetisch sortierten Registereinträgen gibt es jeweils auch die Kategorie „nicht identifiziert“, unter der alle Namen von Personen, Orten und Werken aufgeführt sind, die nicht identifiziert werden konnten.
Die Einträge sind immer gleich strukturiert und beinhalten:
-
einen Abschnitt „Allgemeine Informationen“ mit den Basisinformationen;
-
einen Abschnitt „Zusätzliche Informationen“ mit weiterführenden Hinweisen bzw. Beschreibungen und bibliografischen Angaben;
-
einen Abschnitt „Erwähnungen“, der Aufschluss darüber gibt, in welchen der sechs Texte der Eintrag vorkommt.
- Zudem werden bei einem Personeneintrag alle Orte und Werke aufgelistet, mit denen der Name dieser Person in Zusammenhang steht.
- In einem Ortseintrag wird auf Werke verwiesen, die an diesem Ort waren oder sich noch dort befinden.
Die Identifizierung von Personen, Orten und Werken wurde von den wissenschaftlichen Mitarbeiterinnen und Mitarbeitern vorgenommen. Die Einleitungstexte zu jeder Textedition, die über die Rubrik „Quellenkorpus“ im Drop-down-Menü „Edition“ erreichbar sind, listen im Abschnitt „Bearbeiter*innen“ jeweils alle Zuständigkeiten genau auf.
Es sei betont, dass die Register keine erschöpfenden Daten bereitstellen wollen, sondern lediglich dazu bestimmt sind, verifizierte Basisinformationen zu liefern und auf ergänzende Informationsquellen zu verweisen — vor allem bei Personen, Orten und Werken, die weniger bekannt sind. Wo immer möglich, haben wir einen Link zu einem Online-Repositorium angegeben und eine eng begrenzte Zahl an bibliografischen Referenzen angeführt.
In den Registern sind erfasst:
-
791 Personen, von denen 163 nicht identifiziert werden konnten;
-
1415 Orte, von denen 1245 geolokalisiert sind und 130 nicht identifiziert werden konnten;
-
546 Werke, von denen 72 nicht identifizierbar waren.
Personenregister
Alle in den Editionen genannten Personen wurden indexiert, unabhängig davon, ob sie mit ihrem Vor- und/oder Nachnamen erwähnt werden. Allerdings wurden Personen, die in Kunstwerken dargestellt sind, nicht aufgenommen, ebenso wenig wie literarische, mythologische oder biblische Gestalten. Heilige, soweit sie für die inhaltliche Erschließung der Texte von Interesse sind, wurden jedoch aufgenommen.
Allgemeine Informationen
Kategorie: Die Personen wurden in folgende sechs Kategorien unterteilt. Lediglich 33 der indexierten, aber nicht identifizierbaren Personen konnten keiner dieser Kategorien zugewiesen werden.
| Kategorie (Französisch) | Kategorie (Deutsch) | Identifiziert | Nicht identifiziert | Gesamt |
|---|---|---|---|---|
| Dirigeants et princes | Herrscher und Fürsten | 134 | 1 | 135 |
| Membres du gouvernement et de l’administration | Regierungs- und Verwaltungsmitglieder | 120 | 21 | 141 |
| Savants et hommes de lettres | Gelehrte und Schriftsteller | 41 | 0 | 41 |
| Ecclésiastiques | Kirchliche Würdenträger | 56 | 5 | 61 |
| Artistes | Künstler | 232 | 4 | 236 |
| Autres | Andere | 45 | 99 | 144 |
| (sans catégorie) | (Ohne Kategorie) | 0 | 33 | 33 |
| Gesamt | 628 | 163 | 791 |
Öffentliches Verzeichnis: Wir haben vor allem die Repositorien Biblissima, Kaiserhof und Höfe (Datenbank), VIAF und Wikidata verwendet; siehe unten eine vollständige Liste der dokumentarischen und elektronischen Ressourcen.
Nationalität: Aufgrund der von den heutigen Grenzziehungen abweichenden geografischen Gegebenheiten haben wir unter anderem folgende Präzisierungen vorgenommen: österreichisch (Böhmen); österreichisch (österreichische Linie der Habsburger); britisch (Haus Hannover); spanisch (spanische Linie der Habsburger); italienisch (Savoyen); flämisch (Spanische Niederlande); flämisch (Fürstentum Lüttich); niederländisch (Burgundische Niederlande) für die Zeit vor 1580; niederländisch (Vereinigte Provinzen) für die Zeit nach 1580.
Funktionen: Wir haben bis zu vier verschiedene Funktionen angegeben; bei Personen aus der Zeit der hier editierten Autoren haben wir uns weitgehend auf die Angabe derjenigen Funktionen beschränkt, die sie zum Zeitpunkt der Abfassung des betreffenden Textes innehatten. Auch Adels- und Herrschertitel werden aufgeführt.
Geburts-/Sterbedatum: Wird mit Jahr, Monat, Tag angegeben (JJJJ-MM-TT).
Geburts-/Sterbeort: Wird mit den heute gebräuchlichen Namen der betreffenden Städte und Länder angegeben.
Zusätzliche Informationen: Für 293 der 751 erfassten Personen gibt es eine Beschreibung. Hier finden sich zusätzliche Informationen zu den ausgeübten Funktionen, bibliografische Hinweise, die zur Identifizierung einer Person beitragen können (mit Links zu digitalisierten Quellen, sofern vorhanden), Informationen zu ehelichen, familiären oder sonstigen Verbindungen (Künstlerdynastien oder Meister-Schüler-Beziehungen) sowie Verweise auf weitere Datenbanken (base biographique du Centre de recherche du château de Versailles; RKDartists&). Bei den nicht identifizierten Personen wird zuweilen ein Vorschlag zu deren Identifizierung gemacht, unter Angabe der Quelle.
In der Kategorie „nicht identifiziert“ wird die Person mit ihrem Titel, der Funktion und/oder der Nationalität aufgelistet, die der Autor angibt.
Beispiel für einen Personeneintrag
Ortsregister
Neben den geografischen Orten umfasst dieser Index vor allem Gebäude und architektonische Werke (siehe Liste der Kategorien weiter unten), mit Ausnahme von Skulpturen, die im Werkverzeichnis aufgeführt sind.
Allgemeine Informationen
Kategorie: Alle Ortsnamen wurden den nachstehend aufgeführten zehn Kategorien zugewiesen. Mit Ausnahme der Kategorie „Wohngebäude (Innenräume)“ werden diese auch für die Unterscheidung der Ortstypen bei der Visualisierung der Routen der Reisenden durch Europa und Frankreich verwendet (siehe die „Reiseverläufe“ im Drop-down-Menü „Visualisierungen“).
| Kategorie (Französisch) | Kategorie (Deutsch) | Abgedeckte Typen und Begriffe | Identifiziert | Nicht identifiziert | Gesamt |
|---|---|---|---|---|---|
| Lieux géographiques | Geografische Orte | Kontinent, Land, Insel, Fluss, Berg, Ebene, Stadt, Dorf, Weiler... | 398 | 1 | 399 |
| Infrastructures | Infrastruktur | Avenue, Allee, Innenhof, Boulevard, Straße, Gasse, Hafen, Kai, Tor, Turm, Platz, Springbrunnen, Brunnen, Vorort, Stadtteil, Insel (Paris), Brücke, Aquädukt, Tunnel, Stausee, Hafenbecken, Kanal... | 215 | 26 | 241 |
| Édifices publics | Öffentliche Gebäude | Akademie, Rathaus, Amphitheater, Theater, Bibliothek, Oper, Sternwarte, Gefängnis, Galgen, Jeu de paume, Bäder, Kolleg, Universität, Fakultät, Münzstätte, Jahrmarkt, Markt, Börse, Königliche Manufaktur... | 72 | 8 | 80 |
| Monuments | Monumente | Triumphbogen, Säule, Obelisk, Pyramide | 10 | 2 | 12 |
| Édifices domestiques | Wohngebäude | Palais, Wohnhaus, Stadtpalais, Schloss, Kabinett (Sammlung, Kuriositäten), Privatbibliothek | 168 | 16 | 184 |
| Édifices domestiques (intérieurs) | Wohngebäude (Innenräume) | Raumaufteilung innerhalb eines Wohngebäudes | 97 | 11 | 108 |
| Édifices religieux | Religiöse Gebäude | Kapelle, Kirche, Kathedrale, Basilika, Kloster, Konvent, Abtei, Priesterseminar, Noviziat, Krankenhaus, Nekropole, Friedhof, religiöse Einrichtung... | 197 | 18 | 215 |
| Constructions militaires | Militäreinrichtungen | Arsenal, Fort, Bastion, Zitadelle, Festung, Kaserne(n), Waffen- und Munitionsdepot, Gießerei... | 52 | 0 | 52 |
| Parcs et jardins | Parks und Gärten | Gartenanlage, Park, Boskett, Bassin, Teich, Orangerie, Menagerie, Gartenpavillon, Grotte, | 70 | 4 | 74 |
| Autres lieux | Andere Orte | Spinnerei, Mühle, Glasmanufaktur, Schlachthaus, Tuchhalle, Gasthaus, Hotel, Post, Zunfthaus... | 6 | 44 | 50 |
| Gesamt | 1285 | 130 | 1415 |
Öffentliches Verzeichnis: Wir haben vor allem die Repositorien data.bnf, Getty Thesaurus of Geographic Names (TGN) und Wikidata verwendet; siehe unten eine vollständige Liste der dokumentarischen und elektronischen Ressourcen.
Aktueller Ortsname: Es wird der Name, mit dem der Ort oder das Gebäude heute identifiziert wird, angegeben.
Historischer Ortsname: Angegeben wird der vormals gebräuchliche Namen, sofern dieser vom aktuellen Namen abweicht. Es können auch mehrere historische Namen aufgelistet werden.
Funktion: Eine präzisierende Angabe erfolgt lediglich bei einigen ehemaligen Privathäusern und bei den königlichen Residenzen, um diese von den übrigen Schlössern abzuheben, oder wenn der Ortsname über die Nutzung nicht bereits explizit Auskunft gibt. Nutzungsänderungen wurden vor allem für das 17. und 18. Jahrhundert notiert, in Ausnahmefällen auch zeitlich darüber hinaus.
Zustand: Der „Ort“ kann erhalten, teilweise erhalten, zerstört oder teilweise zerstört bzw. aufgelöst (z. B. eine Akademie oder eine Sammlung) sein.
Künstler/Autor(en): Hier werden bis zu drei der wichtigsten
Architekten, Maler und Bildhauer aufgeführt, die mit dem Bau in
Verbindung stehen. Die teilweise hinzugefügte Ergänzung „et al.“
verweist gerade bei Bauten mit komplexer Entstehungsgeschichte
(Kathedralen, königliche Residenzen usw.) darauf, dass natürlich
wesentlich mehr, teilweise auch nicht benennbare Künstler an einem Werk
beteiligt waren. Wenn die hier erwähnten Künstler auch im
Personenregister nachgewiesen sind, wird eine entsprechende Verlinkung
angeboten, gekennzeichnet durch das Symbol
 ; ansonsten verlinken wir — soweit verfügbar — mit einem Repositorium,
kenntlich durch das Symbol
; ansonsten verlinken wir — soweit verfügbar — mit einem Repositorium,
kenntlich durch das Symbol
 .
.
Chronologie: Hier werden die wichtigsten Daten der Errichtungen, Umbauten und Zerstörungen vornehmlich bis zum Ende des 18. Jahrhunderts angegeben. In einigen Fällen wird zeitlich auch weiter ausgegriffen (so etwa bei bedeutenden Transformationen oder Zerstörungen infolge von Kriegen oder Bränden usw.).
Geolokalisation: Angabe der geografischen Koordinaten (Breiten- und Längengrad) in Dezimalgrad (DG), mit Verweis auf Google Maps. Diese Koordinaten wurden für die Visualisierung der von den Reisenden benutzten Routen und aufgesuchten Orte verwendet (siehe im Drop-down-Menü „Visualisierungen“ „Reiseverläufe“). Bei Innenräumen und Gärten haben wir mit wenigen Ausnahmen die Geolokalisierung des jeweiligen Hauptgebäudes übernommen. Bei Institutionen (z. B. Akademien) haben wir meist keine Geolokalisierung angegeben, weil diese im Laufe weniger Jahrzehnte häufig umgezogen sind und sich damit an mehreren Standorten befunden haben.
Zusatzinformationen: Eine Beschreibung ist 367 Orten bzw. Gebäuden beigegeben, unter den insgesamt 1403 indexierten. Bewusst wurde eine Auswahl getroffen und vor allem weniger bekannte Sakralbauten, private Herrenhäuser, einige Plätze, Tore, Brücken und Denkmäler sowie Innenräume von Residenzen und Schlössern berücksichtigt. Bekannte Stätten haben wir nicht kommentiert, weil die Repositorien ausreichende Informationen bieten. Für manche Stätten, zu denen es keine verlässlichen oder aktuellen Informationsquellen gab, haben wir auf Germain Brice (Description nouvelle de la ville de Paris, Ausgaben von 1698 und 1706), Pierre Le Muet (Manière de bien bastir pour toutes sortes de personnes) oder einen anderen zeitgenössischen Text zurückgegriffen. Wenn die Reisenden die Ausstattung eines Innenraums (Deckengestaltung, Wandmalereien usw.) kommentiert haben, wird darauf durch einen entsprechenden Satz hingewiesen, da dies aus der Rubrik „Erwähnungen“ nicht gleich ersichtlich ist.
Die Kirchen der Klöster und Abteien haben wir nicht eigens indexiert, sondern uns für einen einzigen Eintrag entschieden, der sich auf die gesamte Klosteranlage oder Abtei bezieht: Die Reisenden hatten vorwiegend Zugang zu den Konvents- oder Abteikirchen.
Beispiel für einen Ortseintrag

Werkregister
Es wurden nur bewegliche Werke indexiert; Wandmalereien, Fresken, bemalte Decken und andere feste Dekorationen wurden ausgeschlossen, um den Umfang des Registers überschaubar zu halten. Informationen zu solchen Ausstattungselementen finden sich vereinzelt sowohl im Werk- als auch im Ortsregister unter den „Zusatzinformationen“ (etwa zur Kuppelausmalung der Abteikirche Val-de-Grâce oder der Tapisserieserie der Geschichte der hll. Gervasius und Protasius).
Allgemeine Informationen
Kategorie: Die Werke wurden in folgende fünf Kategorien unterteilt:
| Kategorie (Französisch) | Kategorie (Deutsch) | Identifiziert | Nicht identifiziert | Gesamt |
|---|---|---|---|---|
| Peinture | Malerei | 222 | 31 | 252 |
| Sculpture | Plastik | 146 | 21 | 167 |
| Gravure | Grafik | 41 | 6 | 47 |
| Livres | Bücher | 42 | 1 | 43 |
| Autres | Andere | 24 | 13 | 37 |
| Gesamt | 475 | 72 | 546 |
Öffentliches Verzeichnis: Wir haben vor allem folgende Repositorien verwendet: die Datenbank AGORHA des INHA, den Katalog der BnF, HEIDI, Gallica, OBVSG (Österreichischer Bibliothekenverbund und Service GmbH), VIAF, Wikidata, die Sammlungsdatenbank des Château de Versailles, die Datenbank der Sammlungen des Musée du Louvre, die digitale Bibliothek des INHA, den Catalogue des sculptures des jardins de Versailles et de Trianon (Katalog der Skulpturen der Versailler Gärten und des Trianon); siehe unten die vollständige Liste der dokumentarischen und elektronischen Ressourcen.
Künstler/Autor(en): Wenn der betreffende Künstler/Autor auch im
Personenregister nachgewiesen ist, wird eine entsprechende Verlinkung
angeboten, gekennzeichnet durch das Symbol
; ansonsten verlinken wir — soweit verfügbar — mit einem Repositorium,
kenntlich durch das Symbol
 .
.
Datum: Hier werden Angaben zur Datierung des Werks gemacht.
Aktueller Zustand: Es wird angegeben, ob das Werk erhalten oder teilweise erhalten, zerstört oder teilweise zerstört, teilweise ausgeführt oder verschollen ist.
Aktueller Aufbewahrungsort: Hier wird der Ort angegeben, an dem sich
das Werk heute befindet. Ist dieser im Ortsregister indexiert, erscheint
das
Symbol .
.
Ehemaliger Aufbewahrungsort: Hier wird der Ort angegeben, an dem
sich das Werk früher befand. Ist dieser im Ortsregister indexiert,
erscheint das
Symbol.
Material und Technik: Die verschiedenen zur Herstellung des Werks verwendeten Materialien und Techniken werden aufgeführt.
Maße: Diese werden stets in Zentimetern angegeben (meist Höhe x Breite); bei komplexen Ensembles (z. B. Grabdenkmäler, die eine große Anzahl von Elementen umfassen) geben wir in der Regel die Gesamtmaße an und/oder die der bedeutendsten Elemente bzw. Skulpturen.
Zusatzinformationen: Eine Beschreibung haben 504 der 546 indexierten Werke erhalten. Diese Beschreibung enthält hauptsächlich Informationen zum Kontext und zum Bestand (Näheres über den Auftrag und den Erhaltungszustand). Es liegt in der Natur der Sache, dass wir Werke, die zerstört wurden oder verschwunden sind, oft umfassender beschreiben, um so ihre Geschichte besser zu vermitteln.
Beispiel eines Werkeintrags

Webressourcen
Nachfolgend werden alle webbasierten Ressourcen aufgelistet, die zur Registererstellung verwendet wurden (Repositorien, Bibliothekskataloge, Thesauri, Inventare, Sammlungsdatenbanken usw.). Die im Projekt ARCHITRAVE verwendete Literatur ist im Drop-down-Menü „Edition“ unter der Rubrik „Bibliografie“ zu finden.
Allgemeine Ressourcen
- Authority records for persons, printers, corporate entities and places until approx. 1830 (CERL Thesaurus): https://data.cerl.org/thesaurus/_search
- Data.bnf.fr (Referenzinformationen zu Autoren, Werken, Themen der Bibliothèque nationale de France): https://data.bnf.fr
- Identifiants et Référentiels pour l’enseignement supérieur et la recherche (IdRef) (Identifikatoren und Repositorien für Hochschullehre und Forschung): https://www.idref.fr/
- Virtual International Authority File (VIAF): https://viaf.org/
- Wikidata: https://www.wikidata.org/
- Wikipedia: https://de.wikipedia.org/
Spezifische Ressourcen
Personen
- Annuaire prosopographique de la France savante (CTHS) (Alphabetisches prosopografisches Verzeichnis des gelehrten Frankreichs): http://cths.fr/an/prosopographie.php
- Base biographique du CRCV (Biografische Datenbank des Centre de recherche du château de Versailles): http://www.chateauversailles-recherche-ressources.fr/jlbweb/jlbWeb?html=accueildictionnaire
- Base de données « acteurs » de l’époque moderne, projet Symogih (Datenbank „Akteure“ der Neuzeit, Projekt Symogih): http://symogih.org/?q=actors-list&lang=fr
- Biblissima, das Observatorium für das schriftliche Kulturerbe des Mittelalters und der Renaissance: https://biblissima.fr/
- Biografische Datenbank AGORHA des Institut national d’histoire de l’art: https://agorha.inha.fr/
- Biografisch Portaal van Nederland: http://www.biografischportaal.nl/
- Deutsche Biographie: https://www.deutsche-biographie.de/
- Deutsche Nationalbibliothek (DNB): https://www.dnb.de/DE/Home/home_node.html
- Germania Sacra - Digitales Personenregister: http://germania-sacra-datenbank.uni-goettingen.de/
- Getty Union List of Artist Names (ULAN): https://www.getty.edu/research/tools/vocabularies/ulan/
- Kunstindeks Danmark / Weilbach Dansk Kunstnerleksikon: https://www.kulturarv.dk/
- Personendatenbank der Höflinge der österreichischen Habsburger des 16. und 17. Jahrhundert: https://kaiserhof.geschichte.lmu.de/
- Bases Architecture et Patrimoine du Ministère de la Culture et de la Communication (Datenbank Architektur und Kulturerbe des Ministeriums für Kultur und Medien): http://www2.culture.gouv.fr/culture/inventai/patrimoine/
- Répertoires biographiques d’artistes (Allgemeines Künstlerlexikon - Internationale Künstlerdatenbank — Online): https://bnf.libguides.com/artiste
- Repertorium der diplomatischen Vertreter aller Länder seit dem Westfälischen Frieden (1648), Bd. I: 1648-1715, hg. v. Ludwig Bittner u. Lothar Groß unter Mitwirkung v. Walther Latzke, Oldenburg u. Berlin: Gerhard Stalling, 1936
- Repertorium der diplomatischen Vertreter aller Länder seit dem Westfälischen Frieden (1648), Bd. II: 1716-1763, hg. v. Friedrich Hausmann unter Leitung v. Leo Santifaller u. unter Mitarbeit v. Lothar Groß u. Edith Kotasek, Zürich: Fretz & Wasmuth, 1950
- Database of Dutch and Foreign artists from the Middle Ages to today (RKDartists), erstellt vom Rijksbureau voor Kunsthistorische Documentatie in Den Haag: https://rkd.nl/en/explore/artists
Orte
- Archinform — Base de données d’architecture internationale (Internationale Architektur-Datenbank): https://deu.archinform.net/index.htm
- Archipedie — Encyclopédie numérique collaborative sur l’architecture moderne et contemporaine (Kollaborative Web-Enzyklopädie der modernen und zeitgenössischen Architektur): http://archipedie.citedelarchitecture.fr/
- Base de données des collections du musée des Monuments français (Datenbank der Sammlungen des Musée des Monuments français): https://collections.citedelarchitecture.fr/
- Base Mérimée (patrimoine architectural) (Datenbank Mérimée, architektonisches Kulturerbe): https://www.pop.culture.gouv.fr/search/list?base=%5B%22Patrimoine%20architectural%20%28M%C3%A9rim%C3%A9e%29%22%5D
- Carte de France de Cassini (Frankreichkarte von Cassini): http://cassini.ehess.fr/cassini/fr/html/index.htm
- Census of Antique Works of Art and Architecture Known in the Renaissance: https://database.census.de/search
- Corpus des hôtels parisiens du XVIIe siècle : inventaires après décès de 24 hôtels (Korpus der Pariser Hôtels des 17. Jahrhunderts: Nachlassverzeichnisse der Inhaber von 24 Hôtels): https://www.centrechastel.sorbonne-universite.fr/ressources/ressources-documentaires/corpus-et-bases-de-donnees/sources-et-corpus-publies-en-ligne
- Corpus Inscriptionum Latinarum: https://fr.wikipedia.org/wiki/Corpus_Inscriptionum_Latinarum
- Dictionnaire topographique de la France (Topografisches Lexikon Frankreichs) (CTHS): https://dicotopo.cths.fr/
- EDCS Epigraphik-Datenbank Clauss / Slaby: https://db.edcs.eu/epigr/epi.php?s_sprache=de
- Forte Cultura - Kulturroute Festungsmonumente: https://www.forte-cultura.eu/en/festungen-en/architektur/stadtfestungen
- Geonames: http://www.geonames.org/
- Geoportail (Geoportal): https://www.geoportail.gouv.fr/
- Getty Thesaurus of Geographic Names (TGN): https://www.getty.edu/research/tools/vocabularies/tgn
- Glossaire de l’édition numérique de François Lemée, Traité des Statuës, Paris, 1688, éd. critique par Diane H. Bodart et Hendrik Ziegler, Weimar: VDG, 2012 (Glossar der digitalen Ausgabe von François Lemée, Traité des Statuës, Paris 1688, kritische Ausgabe von Diane H. Bodart und Hendrik Ziegler, VDG: Weimar, 2012): https://asw-verlage.de/lemee (Zugang nur bei Erwerb)
- Liste des églises disparues de Paris (Liste der nicht mehr vorhandenen Pariser Kirchen): https://fr.wikipedia.org/wiki/Liste_des_%C3%A9glises_disparues_de_Paris
- Liste des hôtels particuliers parisiens (Liste der Pariser Stadtpalais): https://fr.wikipedia.org/wiki/Liste_des_h%C3%B4tels_particuliers_parisiens; https://commons.wikimedia.org/wiki/List_of_h%C3%B4tels_particuliers_in_Paris
- Observatoire du patrimoine religieux — Inventaire (Beobachtungsstelle für das religiöse Erbe — Inventar): https://www.patrimoine-religieux.fr/
- Old Maps online: https://www.oldmapsonline.org/
- Paris Data — Voies, nomenclature des voies actuelles: https://opendata.paris.fr/explore/dataset/denominations-emprises-voies-actuelles/information/?disjunctive.siecle&disjunctive.statut&disjunctive.typvoie&disjunctive.arrdt&disjunctive.quartier&disjunctive.feuille
- POP, la plateforme ouverte du patrimoine: https://www.pop.culture.gouv.fr/
- Registres de la Comédie-Française (Archive der Comédie-Française): https://www.cfregisters.org/
- Structurae — Base de données et galerie internationale d’ouvrages d’art et du génie civil (Structurae — Datenbank und internationale Bildergalerie für Architektur und Ingenieurbau): https://structurae.net/
Werke
- Bilddatenbank des Centre de recherche du château de Versailles: http://www.banqueimages.chateauversailles-recherche.fr/
- Datenbanken des Centre de recherche du château de Versailles (Base bibliographique und Base biographique): http://www.chateauversailles-recherche-ressources.fr/jlbweb/jlbWeb?html=accueilarticles ; http://www.chateauversailles-recherche-ressources.fr/jlbweb/jlbWeb?html=accueildictionnaire
- Catalogue des sculptures de Versailles et de Trianon (Katalog der Skulpturen der Versailler Gärten und des Trianon): https://sculptures-jardins.chateauversailles.fr/
- Census of Antique Works of Art and Architecture Known in the Renaissance: https://database.census.de/search
- Datenbanken AGORHA des Institut national d’histoire de l’art: https://agorha.inha.fr/
- Digitale Bestände der Universitätsbibliothek Heidelberg: https://digi.ub.uni-heidelberg.de/
- Digitale Bibliothek des Institut national d’histoire de l’art (INHA): https://bibliotheque-numerique.inha.fr/
- Digitale Sammlungen der Herzogin Anna Amalia Bibliothek (HAAB), Weimar: https://haab-digital.klassik-stiftung.de/viewer/index/
- Digitaler Portrait Index: https://portraitindex.de/
- Europeana: https://www.europeana.eu/de
- Galerie des Glaces — Catalogue iconographique (hg. v. Nicolas Milovanovic): https://galeriedesglaces-versailles.fr/html/11/accueil/index.html
- Gallica: https://gallica.bnf.fr/
- HathiTrust Digital Library: https://www.hathitrust.org/
- HEIDI — Online-Katalog der Universitätsbibliothek Heidelberg (HEIDI): https://katalog.ub.uni-heidelberg.de/
- Internet Archive: https://archive.org/
- Joconde — Catalogue des collections des musées de France (Katalog der Sammlungen der französischen Museen): https://www.pop.culture.gouv.fr/search/mosaic?base=%5B%22Collections%20des%20mus%C3%A9es%20de%20France%20%28Joconde%29%22%5D&image=%5B%22oui%22%5D
- Karlsruher Virtueller Katalog (KVK): https://kvk.bibliothek.kit.edu
- Katalog der Bibliothèque nationale de France (BnF): https://catalogue.bnf.fr/
- K10plus-Verbundkatalog: https://opac.k10plus.de/
- Les vocabulaires du Ministère de la Culture et de la Communication (Fachterminologien des Ministeriums für Kultur und Kommunikation): http://data.culture.fr/thesaurus/
- Moteur Collections du ministère de la Culture (Moteur Collections des Ministeriums für Kultur): https://www.culture.fr/Moteur-Collections
- OPACplus Bayerische Staatsbibliothek: https://opacplus.bsb-muenchen.de/
- Österreichischer Bibliothekenverbund und Service GmbH (OBVSG): https://www.obvsg.at/
- Palissy — Base patrimoine mobilier (Datenbank für bewegliches Kulturgut): https://www.pop.culture.gouv.fr/search/mosaic?base=%5B%22Patrimoine%20mobilier%20%28Palissy%29%22%5D&image=%5B%22oui%22%5D
- POP, la plateforme ouverte du patrimoine: https://www.pop.culture.gouv.fr/
- Portail Collections du château de Versailles (Portal Sammlungen des Schlosses Versailles): http://collections.chateauversailles.fr/
- Portail Collections du musée du Louvre (Portal der Louvre-Sammlungen): https://collections.louvre.fr/
- Versailles décor sculpté extérieur (dir. Béatrix Saule) (Versailler Fassaden-Skulpturenschmuck — Leitung Béatrix Saule): https://sculpturesversailles.fr/
- Virtuelles Kupferstichkabinett: http://www.virtuelles-kupferstichkabinett.de/
Autorin: Alexandra Pioch