Normes éditoriales
Pour les six documents, nous avons procédé à une transcription dite diplomatique, autrement dit à une reproduction dactylographique respectant aussi fidèlement que possible la graphie et la topographie des unités écrites, chacune figurant à la même place de la page que sur l’original. Les majuscules, les divisions de mots, l’espacement et la ponctuation ont en particulier été restitués avec des modifications et interprétations éditoriales réduites au minimum. Dans les cas impossibles à trancher, nous avons opté pour la graphie actuelle.
Des enrichissements rédactionnels ont été insérés dans l’ensemble des
textes afin d’en améliorer la lisibilité. Les symboles et ajouts
rédactionnels peuvent être affichés ou masqués dans le menu déroulant «
Options d’affichage » (signalé par
l’icône ),
situé dans la barre d’outils horizontale, à droite de celui des
vues/pages. Introduits par les éditeurs et éditrices pour enrichir et
faciliter la lecture, ces marques et symboles éditoriaux sont
explicites : leur signification peut être consultée en cliquant sur le
menu intitulé « Informations éditoriales »
(icône
),
situé dans la barre d’outils horizontale, à droite de celui des
vues/pages. Introduits par les éditeurs et éditrices pour enrichir et
faciliter la lecture, ces marques et symboles éditoriaux sont
explicites : leur signification peut être consultée en cliquant sur le
menu intitulé « Informations éditoriales »
(icône )
dans la barre d’outils horizontale. Les principes suivants méritent
cependant d'être précisés :
)
dans la barre d’outils horizontale. Les principes suivants méritent
cependant d'être précisés :
- Les flexions ou terminaisons des mots allemands (en « -en » ou « -er ») ont été transcrites au long même si elles n’apparaissent que sous forme abrégée ou sont non visibles dans l’original.
- Les mots abrégés ont été transcrits et encodés comme tels ; dans la plupart des cas, leur résolution ou développement au long sont également proposés. Ce faisant, nous avons choisi de conserver l’orthographe propre à chaque auteur, même si celle-ci diffère de l’orthographe actuelle. Ainsi, « jun. » peut correspondre au long à « juny » (aujourd’hui Juni [juin]), « Oct. » à « October » (aujourd’hui Oktober), ou encore « ent. » à « entlich » (aujourd’hui endlich [enfin]). Le menu déroulant « Options d’affichage » permet de choisir entre la vue présentant les abréviations et celle avec les mots écrits au long. Certaines abréviations plus fréquentes et plus explicites n’ont toutefois pas été développées (par exemple, « Fig./fig. » pour « figure » [Tab./tab. en allemand]).
- Il en va de même pour l’orthographe des mots agglutinés,
particulièrement fréquents dans le manuscrit de Lambert Friedrich
Corfey. Dans la vue par défaut, ces mots sont affichés séparément,
conformément à l’orthographe actuelle. Il est aussi possible d’opter
pour une vue où s’affiche l’ensemble des graphies agglutinées du
document original, qui sont alors signalées dans le texte par le
symbole
 .
Quand on positionne le curseur sur le ou les mots concernés, ceux-ci
s’affichent dans une info-bulle : sous leur forme séparée, si l’option
« Afficher les mots agglutinés » est cochée, sous leur forme agrégée,
si cette option est décochée.
.
Quand on positionne le curseur sur le ou les mots concernés, ceux-ci
s’affichent dans une info-bulle : sous leur forme séparée, si l’option
« Afficher les mots agglutinés » est cochée, sous leur forme agrégée,
si cette option est décochée.

- Les barres obliques « / », qui représentent en réalité des virgules, ont été remplacées en conséquence, notamment dans la transcription du livre de Leonhard Christoph Sturm. Voici un exemple vue 5 :

- Cependant, lorsqu’elles sont utilisées pour marquer la fin d’un vers ou d’une ligne, elles ont été conservées. Dans les inscriptions latines, le soulignement entre deux membres de phrase signale généralement aussi un saut de ligne (par exemple chez Corfey). Voici un exemple vue 13 :

- Les lettres et les mots qui n’ont pu être clairement identifiés sont signalés comme étant « non élucidés », par l’ajout d’un point d’interrogation entre crochets. Voici un exemple dans Harrach, vue 4 :

- Le « c » des combinaisons de lettres « ch » et « sch » a par ailleurs été omis par certains auteurs (Harrach, Corfey et Neumann). Lorsque la présence d’un « c » est suggérée par la graphie, il a été inséré sans autre indication ; dans les autres cas, il a été ajouté entre crochets. Les auteurs (principalement Harrach) omettent aussi volontiers le « e ». Celui-ci est ajouté entre crochets, lorsque sa présence est nécessaire pour clarifier le sens. Souvent, les graphies du « u » et du « v » sont très similaires, par exemple chez Balthasar Neumann. De plus, un « v » est souvent utilisé là où l’orthographe actuelle commande un « u » (comme dans « vndt » [et]). Dans ces cas, l’orthographe avec « v » a été conservée.
- Certains mots sont orthographiés « ff » dans le manuscrit de Harrach, alors qu’il faudrait plutôt écrire « ft ». Nous avons choisi de conserver le double f en y ajoutant un t : par exemple, à la page 475 (vue 21), « öffers » a été remplacé par « öffters » (aujourd’hui öfters : plus souvent) ou, à la page 488 (vue 34), « schrüfflich » a été remplacé par « schrüfftlich » (aujourd’hui schriftlich [écrit, par écrit]). Harrach n’opérant pas de distinction claire entre « den » et « dem » et l’utilisation du datif n’étant généralement pas constante dans son texte, « den » a été adopté presque sans exception dans la transcription.
L’ensemble des textes a été encodé dans le langage de balisage extensible XML (Extensible Markup Language), selon le format défini par la TEI (Text Encoding Initiative). Il est possible d'afficher la vue XML à côté de la transcription en cliquant sur le bouton « </> » de la barre d’outils, intitulé « Afficher l’XML ». Les singularités de tous les textes ont été encodées, mais – afin que les pages demeurent lisibles – elles n’ont pas toujours été rendues visibles. Ainsi, par exemple, les tampons d’archives et de bibliothèques sont encodés mais n’apparaissent pas dans les vues.
Nous avons restitué la mise en page originale, le fac-similé numérisé de chaque page du document, accessible par le bouton « Afficher les fac-similés » pouvant être placé à côté de la transcription. Il convient toutefois de préciser les mentions suivantes :
- Les annotations et les références ajoutées en marge par les
auteurs (principalement Corfey et Sturm) n’apparaissent pas dans une
colonne supplémentaire, mais dans des fenêtres pop-up accessibles en
cliquant sur des bulles blanches à liserés rouges
 ,
placées en début ou fin de ligne.
,
placées en début ou fin de ligne. - Listes et tableaux ont été restitués autant que faire se peut dans leur disposition originale. Lors de leur consultation, il est recommandé d’augmenter la largeur de la fenêtre de la vue synoptique, jusqu’à ce que les passages à la ligne s’affichent comme dans le document original.
- Dans les éditions des textes de Christoph Pitzler, Christian Friedrich Gottlieb von dem Knesebeck et Balthasar Neumann, texte et dessins sont étroitement imbriqués ; dans le cas de Pitzler, cette imbrication est particulièrement complexe. À quelques exceptions près, l’emplacement des sections de texte par rapport aux dessins n’a pas été reproduit dans la transcription. Cependant, pour mieux structurer celle-ci et préserver l’unité de sens de l’original, des intitulés entre crochets ont été attribués à l’ensemble des dessins, ce qui permet d’identifier plus précisément leur contenu. Il s’agit donc ici d’ajouts par les rédacteurs et rédactrices de la transcription. Afin d’assurer le caractère uniforme et univoque de ces titres, les termes techniques utilisés et leur ordre obéissent à une nomenclature et à un schéma prédéfinis, au prix, parfois, d’une formulation un peu contrainte. Les parties de texte associées aux dessins suivent le plus souvent ces intitulés entre crochets, mais, lorsque cela semble plus approprié, ils peuvent aussi les précéder. Il est important de noter que la transcription restitue les ensembles signifiants de chaque page en progressant toujours du haut à gauche, au bas à droite du document original.
- Dans l’ouvrage de Sturm, les informations figurant sous les planches gravées à propos du dessinateur, du graveur et de l’éditeur des gravures (Leonhard Christoph Sturm, Johann August Corvinus et Jeremias Wolff) n’ont pas été transcrites.
- Les chiffres et les dimensions mentionnés dans les dessins n’ont été reproduits que lorsque la clarté de la transcription n’en souffrait pas trop. Dans les éditions des textes de Sturm et de Knesebeck, des annotations entre crochets, introduites sous les intitulés des dessins, attirent l’attention du lecteur sur les transcriptions manquantes de ces mentions chiffrées. Pour le manuscrit de Pitzler, ces annotations ont été omises en raison du grand nombre de dessins. Il est donc fortement recommandé de consulter les fac-similés numérisés en complément. Les auteurs indiquent souvent des mesures en pieds et en pouces : une apostrophe après le chiffre (’) signifiant « pieds » ; deux apostrophes (’’) signifiant « pouces ». Toutefois, il n’est pas précisé à quelle unité de mesure spécifique (à l’époque propre à chaque pays) il est fait référence. On peut néanmoins dire qu’un pied équivaut à environ 30 cm et un pouce à environ 2,5 cm. En dehors de quelques exceptions, nous n’avons pas fait de commentaires supplémentaires ni précisé davantage ces unités de mesure. Le même principe a été appliqué à l’unité de longueur ou « toise » (environ 1,95 m). Quand Corfey ne précise pas l’unité de mesure, on peut supposer qu’il continue à utiliser la dernière unité mentionnée.
- Les lignes horizontales et verticales, qui apparaissent très fréquemment dans le manuscrit de Pitzler pour délimiter les différents dessins, ont été encodées en conséquence. Cependant, seules certaines des lignes horizontales sont visibles sur les vues, partout où leur présence est utile pour clarifier l’organisation de la page. Une approche pragmatique similaire a été adoptée en ce qui concerne la visualisation des lignes pointillées et des lignes doubles horizontales.
- Certains auteurs (principalement Sturm et Knesebeck, et dans certains cas Corfey) ajoutent une syllabe ou un mot à la fin d’une page. Justifiés à droite sur une ligne par ailleurs laissée vierge, ces ajouts servent, soit à terminer la phrase, soit à indiquer le premier mot par lequel commence la page suivante. Toutes ces syllabes ou mots apparaissent dans la présente édition, et sont figurés dans une position semblable à celle occupée dans l’original.
- Les formules finales des lettres (chez Sturm et Neumann) ont été disposées, dans les deux cas, selon une présentation unifiée, même si celle-ci ne correspond pas toujours à la manière dont elles apparaissent dans les documents originaux.
Les cinq manuscrits sont écrits en écriture cursive allemande, tandis que le livre de Leonhard Christoph Sturm a été imprimé en caractères gothiques. Dans les vues, ces écritures et polices apparaissent toutes en caractères latins. Cependant, l’ensemble des auteurs a aussi eu recours à l’écriture latine pour citer des expressions ou des passages en langue étrangère ainsi que des mots d’origine étrangère entrés dans le lexique allemand. Ces utilisations de l’écriture latine sont indiquées dans la présente édition par un changement de police, visible dans le texte courant allemand. Particulièrement fréquentes chez Corfey, Knesebeck et Sturm, les inscriptions latines en majuscules romaines ont été reproduites à l’identique dans la transcription, et sont également signalées par un changement de police.
L’orthographe des inscriptions latines anciennes et contemporaines, figurant sur des monuments ou des édifices, n’a pas été corrigée et, dans certains cas, les auteurs les ont citées de façon erronée ou abrégée. Dans la traduction française, ces inscriptions ont été reproduites en restant fidèle aux textes allemands. Il convient de souligner qu’il n’a pas été possible de fournir une traduction complète de la totalité d'entre elles (et des quelques inscriptions en grec ancien également citées). C'est donc seulement dans certains cas qu’une traduction a été ajoutée dans une note, à la fin de l’inscription.
Les documents contiennent parfois des ajouts manuscrits qui ne sont pas de la main de l’auteur, mais de celle d’un secrétaire ou d’un archiviste (c’est notamment le cas dans les lettres de Neumann). Ces ajouts ont été reproduits en gris clair, de manière à les rendre plus faciles à distinguer.
Dans le menu déroulant des vues/pages, le chiffre en blanc sur fond noir, devenant rouge quand on y positionne le curseur, indique le numéro de la vue d’édition consultée. En cliquant sur les flèches situées à droite et à gauche du numéro, il est possible de feuilleter l’édition du document, en avant comme en arrière. En cliquant sur le numéro lui-même, on ouvre un menu déroulant qui permet une navigation plus rapide dans l’ensemble du document.
- À la numérotation de chaque « vue », attribuée par nos éditeurs et éditrices, a été annexée entre parenthèses la pagination ou la foliotation du document d’époque, due à l’auteur ou à un archiviste.
- Les deux numéros diffèrent généralement l’un de l’autre, notamment quand certaines feuilles du document original ont été perdues (comme dans le cas de Pitzler), ou lorsque la position de certaines pages a été modifiée par les éditeurs et éditrices du présent document (comme dans le cas de Neumann), autrement dit quand la numérotation d’archive n’a pas été respectée.
- Dans le cas d’une foliotation, la mention précisant s’il s’agit du recto ou du verso d’une feuille figure, à titre d’information supplémentaire, sous la forme d’un r ou d’un v entre crochets.
Le moteur de recherche peut être activé en cliquant sur la loupe située en haut à droite dans l’en-tête du site, à côté du sélecteur de langue. Il permet, entre autres, la recherche de séquences de mots (qui doivent être saisies entre guillemets) dans l’ensemble des éditions, dans les entrées d’index, les textes d’introduction et d’accompagnement, mais pas dans les notes (marginales, scientifiques ou de traduction). Les listes de résultats permettent une première analyse de textométrie, et donnent un aperçu quantitatif sommaire de la fréquence de certains choix syntaxiques et sémantiques. Il convient de rappeler que le sens de certains mots a bien sûr évolué au fil des siècles. Le dictionnaire allemand de Jacob et Wilhelm Grimm, publié en ligne par l’université de Trèves, a été à cet égard d’une grande aide. Ainsi, à l'époque, l’adjectif orthographié « schlecht », qui apparaît 70 fois dans l’édition, signifie non seulement « mauvais » mais prend aussi souvent le sens de l’actuel « schlicht » (simple, modeste), dont il constitue l’origine étymologique ; voir https://www.dwds.de/wb/etymwb/schlicht). Pour une meilleure compréhension des textes allemands, nous recommandons donc de consulter également les traductions françaises, où ces glissements de sens ont été pris en compte.
Il existe plusieurs modalités pour citer les présentes éditions :
- En utilisant le menu « Informations éditoriales » de la barre d’outils horizontale, voir la rubrique « Pour citer cette édition ». Pour citer une page en particulier, ajouter le numéro de la vue ainsi que celui de la page ou du folio correspondant à la fin de la référence. L’identifiant persistant ou PID (handle) de chaque édition est donné dans la section « Métadonnées » du menu. En cliquant sur le PID on est dirigé vers l’édition qui est stockée dans le TextGrid Repository. De là, l’édition peut être téléchargée au format HTML et imprimée au format PDF. En outre, on peut effectuer des analyses textométriques sur l'ensemble du corpus grâce aux outils « Voyant Tools ».
- Chaque page individuelle peut également être citée en copiant l’URL qui s’affiche dans le navigateur.
- Chaque note (marginale, scientifique ou de traduction) se voit attribuer un numéro. Cette numérotation recommence à chaque vue par un « 1 ». L’URL propre à chaque annotation peut être copiée depuis la barre d'adresse du navigateur et reprise dans une citation.
- De même, chaque entrée d’index peut être citée en copiant l’URL dans la barre d’adresse du navigateur.
Le site offre donc un affichage dynamique des éditions, s'adaptant aux besoins spécifiques de chacun. Les entrées d’index et les notes viennent enrichir les éditions en proposant des informations complémentaires et des liens vers des ressources externes.
Auteur : Hendrik Ziegler
Des six textes édités sur le site ARCHITRAVE, trois sont inédits (Harrach, Knesebeck et Pitzler). Celui de Sturm a été publié pour la première fois en 1719, le journal de Corfey a fait l’objet d’une première édition critique en 1977 (voir Corfey 1977), et les lettres de Neumann ont été éditées à deux reprises, en 1911 et 1955 (voir Lohmeyer 1911 et Freeden 1955). Pour notre projet d’édition numérique, il était indispensable de proposer une traduction de ces six textes allemands, datant de la fin du XVIIe et du début du XVIIIe siècle, afin de leur offrir une plus grande visibilité auprès de la communauté scientifique, mais également d’un public amateur éclairé. Dans le cadre de ce projet franco-allemand ANR-DFG, réunissant des équipes françaises et allemandes et éditant des récits de voyageurs allemands venus en France sous l’Ancien Régime, le français s’est naturellement imposé comme langue de traduction. Cette transposition en français, qui s’est accompagnée d’une lecture minutieuse et d’un patient travail d’élucidation de textes souvent ardus même pour un lecteur germanophone, constitue un des apports majeurs du projet.
Approche générale et particularités stylistiques de chaque texte
L’équipe du projet a opté pour une approche de traduction offrant la meilleure lisibilité possible. Les textes de ces six sources ne sont pas à proprement parler des textes littéraires et n’ont pas été conçus dans cette intention par leurs auteurs. Ils sont pour la plupart écrits dans un registre de langue quotidien, où l’information prime le style, et dans un allemand de l’époque baroque à l’orthographe encore fluctuante, et parfois émaillé de régionalismes. Ils se distinguent aussi souvent par leur caractère technique. La traduction s’efforce bien sûr d’être le plus fidèle possible à l’original, tout en prenant certaines libertés dans la formulation des passages les plus difficiles à comprendre et en recourant à un lexique et une syntaxe plus modernes, afin de ne pas reproduire inutilement les lourdeurs des textes originaux. Cependant, si nous avons privilégié la lisibilité et la fluidité en français, nous avons aussi cherché à préserver une tonalité d’époque en optant parfois pour un vocabulaire et des tournures anciennes. L’objectif de la traduction est de rendre ces textes accessibles et compréhensibles aux lecteurs francophones et de leur proposer des clés de lecture. Eu égard au caractère hermétique de certains passages, leur traduction relève par force de l’interprétation, le lecteur pouvant à tout moment comparer les versions françaises aux originaux, grâce à l’affichage en vis-à-vis de la transcription et de la traduction.
Il était impossible de confier à un seul traducteur l’ensemble des six textes. Quatre traductrices et un traducteur ont finalement été retenus, après un appel à candidature et un test de traduction : Anna Hartmann en binôme avec Antoine Guémy (Sturm), Isabelle Kalinowski (Knesebeck), Florence de Peyronnet-Dryden (Pitzler et Neumann) et Nicole Taubes (Harrach et Corfey). Les traductions ont débuté en avril 2016 et ont fait l’objet de plusieurs campagnes de révision jusqu’en 2021. En 2019, le traducteur Jean-Léon Muller a rejoint l’équipe.
En effet, des modifications et corrections sont intervenues tout au long de l’établissement de l’édition, au fur et à mesure de l’encodage XML-TEI, de l’indexation et de l’annotation critique des textes allemands et français. Ces étapes ont permis d’affiner le sens des textes et parfois de corriger des erreurs grâce, entre autres, à l’éclairage apporté par l’identification des entités citées (personnes, lieux, œuvres) et par l’établissement de notes scientifiques et de traduction découlant du travail de recherche mené par les éditeurs et les traducteurs. Ce travail de traduction et de révision a été le fruit d’une étroite collaboration entre les traducteurs du corpus et l’équipe éditoriale d’ARCHITRAVE (Florian Dölle, Marion Müller, Alexandra Pioch et Hendrik Ziegler).
Sauf mention contraire, une partie des citations et des inscriptions en latin et dans d’autres langues ont été traduites en français par les traducteurs des textes avec l’aide de l’équipe éditoriale.
Harrach
Le texte de Ferdinand Bonaventure comte de Harrach revêt un caractère plus intime et plus léger que les autres. Entre journal et récit, il témoigne aussi d’un style narratif plus littéraire. Nous nous sommes efforcés de le traduire en conservant le plus possible son caractère vivant.
Pitzler
D’un style plus haché, le texte de Christoph Pitzler est aussi fragmenté par la présence de nombreux dessins, ce qui le rend parfois difficile à comprendre. Nous avons opté pour une traduction proche de l’original allemand, mais il a aussi fallu se laisser guider par l’intuition et recourir à l’interprétation pour les passages les moins clairs.
Corfey
Le texte de Lambert Friedrich Corfey est d’une lecture aisée. Il s’agit d’un journal de voyage qui n’était pas destiné à être publié. Son style est sobre et descriptif, même si de temps à autre l’auteur insère des passages narratifs et anecdotiques qui donnent de la saveur au récit. Nous avons opté pour une traduction assez proche du texte allemand. Celui-ci comporte par ailleurs les transcriptions d’un très grand nombre d’inscriptions latines figurant sur des bâtiments et monuments décrits par Corfey : nous n’en avons traduit qu’une partie, notamment celles qui ont déjà fait l’objet d’une traduction en allemand par Helmut Lahrkamp (voir Corfey 1977).
Vues 64 à 68 (pages 67 à 71), les noms de régiments français ayant participé aux manœuvres à Compiègne ont été normalisés (typographie et orthographe modernes). Vues 140 à 142 (pages 143 à 145), la liste des écluses du canal du Midi a été laissée telle quelle et en note de traduction nous avons indiqué la version modernisée, quand celle-ci a pu être retrouvée et identifiée. Vue 172 (page 175), la liste des noms de navires a été conservée telle quelle, sans modernisation, car Corfey restitue ici une inscription figurant au-dessus des magasins de l’arsenal à Marseille.
Knesebeck
Le texte de Christian Friedrich Gottlieb von dem Knesebeck est très proche de celui de Leonhard Christoph Sturm : Knesebeck, collaborateur de Sturm à Schwerin de 1711 à 1719, a probablement recopié d’anciennes notes de voyage de son supérieur aujourd’hui perdues, soit en vue d’une publication, soit en vue de son propre périple en France entre 1711 et 1713. Cependant son manuscrit diffère considérablement de l’ouvrage de Sturm, publié en 1719, ce dernier ayant lissé son texte pour la publication et nuancé certains jugements sur les arts d’outre-Rhin.
Nous nous sommes efforcés de préserver le caractère plus brut du manuscrit de Knesebeck. Nous avons harmonisé les traductions du texte de Knesebeck et de celui de Sturm à chaque fois que le contenu quasi identique des textes allemands l’exigeait.
Sturm
Leonhard Christoph Sturm étant l’un des théoriciens de l’architecture les plus prolifiques de l’époque baroque, ses « Notes de voyage », imprimées pour la première fois en 1719, relèvent d’un processus éditorial réfléchi et sont enrichies d’illustrations soutenant le propos du livre. Au regard de la notoriété de ce texte déjà publié, nous avons avant tout cherché à le rendre lisible et attrayant pour le lecteur francophone. La traduction prend donc quelques libertés avec la langue de Sturm. Certains passages étant très techniques, nous avons essayé de les rendre compréhensibles en proposant une traduction du vocabulaire architectural en partie élaboré par l’auteur lui-même (par exemple Sturm emploie le terme « Säulen-Stuhl » de sa propre invention pour désigner un « piédestal »). Nous avons pu bénéficier à cet égard de l’expertise d’Anna Hartmann qui a mis à notre disposition son édition annotée des Architectonischen Reise-Anmerckungen réalisée dans le cadre d’un mémoire de maîtrise (voir Hartmann 2000).
Dans le texte imprimé allemand, les commentaires personnels de Sturm et les citations de la Description nouvelle de la ville de Paris de Germain Brice (1698) sont signalés par des caractères typographiques distincts (gras ou maigres). Cette différenciation visuelle n’a été restituée, ni dans la traduction, ni dans la transcription (voir à cet égard nos remarques dans le texte introductif à Sturm).
Neumann
Avec Balthasar Neumann, nous avons affaire à un architecte de tout premier ordre, même si au moment où il écrit ses lettres, il n’a pas encore donné toute la mesure de son talent. Rédigées durant son périple en France en 1723, elles sont adressées à son maître à Wurtzbourg, le prince-évêque Johann Philipp Franz von Schönborn. Neumann utilise un style diplomatique très courtois, dans lequel on perçoit immédiatement son zèle à l’égard de son seigneur. Pour qui ignore l’histoire de la construction du château de Wurtzbourg, il n’est toutefois pas aisé de suivre sa correspondance, d’autant que les plans de cette résidence princière sont encore en gestation au moment de son voyage (voir à cet égard nos remarques dans le texte introductif à Neumann). L’orthographe du jeune officier et architecte est par ailleurs très personnelle, de même que son usage (ou plus exactement son « non-usage ») de la ponctuation. Ses lettres laissent enfin apparaître des traits propres à l’allemand de Franconie (transformation du « p » en « b », comme par exemple dans « Baris » pour « Paris »).
Plus encore que dans les autres textes, la traduction consiste donc à proposer une interprétation qui vise à donner du sens à de nombreux passages plutôt hermétiques. Elle se veut une aide à lecture pour tous les chercheurs francophones ou suffisamment familiers du français.
Présentation, syntaxe, orthographe et ponctuation
Présentation
La présentation de la traduction française ne restitue pas un certain nombre d’éléments présents dans l’original allemand : les ajouts de lettres ou de mots, les syllabes ou mots répétés en fin de page et alignés à droite, les ratures et les abréviations. Elle signale en revanche certains ajouts de texte interlinéaires, ainsi qu’en marge ou en bas de page.
La traduction ne suit pas les retours à la ligne de la transcription allemande, laquelle reproduit la disposition du texte allemand, mais elle reste aussi proche que possible de l’original pour le reste de la mise en page : sauts de ligne et blancs, alinéas et retraits, présentation des listes et tableaux, légendes de dessins et croquis, disposition des citations et des inscriptions latines, tirets, lignes et traits horizontaux. Les coupes de phrases d’une page à l’autre sont conservées au plus proche de l’allemand dans la traduction, même si la syntaxe et l’ordre des éléments diffèrent en français. Les soulignements n’ont été conservés que ponctuellement, notamment pour faciliter le repérage par rapport au texte allemand placé en vis-à-vis ou faire ressortir des éléments dans une page. L’écriture cursive, marquant dans les textes originaux allemands l’emploi de mots étrangers ou des passages en lettres latines et signalée par une police distincte, n’a pas été reproduite dans la traduction.
Les fins de lettres en français, comportant la formule finale, la signature, la formule de politesse et la mention du lieu et de la date (dans Neumann et Sturm) ne reprennent pas strictement l’ordre des éléments ni la disposition de la page allemande.
Certains blancs dans les textes allemands ont été conservés dans la traduction, par exemple Harrach vue 2 (p. 456), notamment lorsque l’auteur avait ménagé un espace pour y ajouter une information a posteriori.
Dans les textes de Neumann et Corfey, en l’absence de paragraphes, nous avons introduit des divisions arbitraires dans l’encodage XML-TEI, à l’aide de la balise <ab/> et des attributs « day » (les dates des lettres ou du journal) ou « theme » (lorsqu’il n’y a pas de date qui structure le texte). Dans la traduction, cette balise, lorsqu’elle se trouve en début de phrase, a été transformée en un retour à la ligne qui n’existe pas dans le texte original allemand et qui n’est pas restitué dans la transcription. Cette division arbitraire permet de structurer la traduction française en paragraphes et de faciliter la lecture (pour en savoir plus sur l’encodage XML-TEI, voir dans la rubrique Normes éditoriales l’onglet « Encodage des textes »).
Ponctuation et typographie
Les textes allemands comportent très peu de ponctuation. Celle-ci est parfois aléatoire, et souvent une virgule relie des membres de phrase sans aucun lien logique (c’est notamment le cas chez Harrach). Pour rendre le texte français plus intelligible, nous avons introduit une ponctuation signifiante (points-virgules, deux points), scindé les phrases, lorsque cela se révélait nécessaire, et rétabli les points finaux en fin de phrase. Nous avons intégré des points d’interrogation dans les phrases interrogatives, et des points d’exclamation dans celles qui étaient manifestement exclamatives. Nous avons également développé les abréviations sans les encoder, par exemple Harrach vue 16 (p. 470) : 122 fl => 122 florins.
L’usage des capitales est très anarchique dans les sources. Nous avons systématiquement rétabli la capitale initiale en début de phrase en français, même lorsqu’il n’y en a pas en allemand, et rectifié les majuscules/minuscules inopportunes dans le fil du texte. Nous n’avons pas conservé les lettres capitales dans Sturm lorsqu’elles sont employées pour mettre en évidence un mot ou un titre dans la page.
Nous avons introduit des guillemets pour encadrer les citations (devises, expressions et propos rapportés au discours direct). En revanche, nous n’avons pas utilisé les guillemets pour encadrer les passages empruntés à la Description nouvelle de la ville de Paris de Germain Brice, dans Sturm, ou à La description du château de Versailles d’André Félibien, dans Pitzler, car les auteurs ne signalent pas clairement ces citations.
L’italique est utilisé ponctuellement dans la traduction française pour
les mots et expressions en langue étrangère. En revanche, il n’est
employé ni pour les titres d’œuvres, visuellement distingués par un
pictogramme en forme de
diamant et
un surlignement au passage de la souris sur le mot ou groupe de mots
concerné, ni pour les transcriptions d’inscriptions latines ou grecques.
et
un surlignement au passage de la souris sur le mot ou groupe de mots
concerné, ni pour les transcriptions d’inscriptions latines ou grecques.
Les cinq manuscrits sont rédigés en écriture cursive allemande (Kurrentschrift ou Kurrent, qui est la forme manuscrite des diverses formes de gothique allemande), tandis que le livre de Leonhard Christoph Sturm a été imprimé en caractères gothiques. Les auteurs ont aussi utilisé l’écriture latine pour citer des mots, expressions ou passages en langue étrangère. Ces deux écritures ont été restituées dans la transcription par deux polices différentes : cette distinction disparaît dans la version française qui n’utilise qu’une seule police.
Orthographe
Dans les textes allemands, les noms propres (de lieux, de personnes ou d’œuvres) sont parfois mal orthographiés. Ces erreurs ont été corrigées dans les traductions. Pour les toponymes et les patronymes identifiés, nous avons toujours utilisé la forme moderne. Certains noms propres ont été mal identifiés par les auteurs : en général, nous avons rectifié l’erreur dans la traduction. Knesebeck, vue 39 (fol. 18r), écrit par exemple « Breteville » au lieu de « Breteuil » : nous avons conservé « Breteville » dans la transcription allemande et corrigé par « Breteuil » dans la traduction ; dans les deux cas, la notice d’index renvoie à la commune de Breteuil.
Les noms d’enseignes, commerces, auberges ou hôtels ont la plupart du temps été normalisés en français (orthographe, majuscules/minuscules).
Les titres d’œuvres (peintures, sculptures, gravures, etc.) françaises ont été restitués en français s’ils figuraient en allemand dans l’original. Les titres de publications (imprimées) et de gravures françaises ont été corrigés et normalisés selon les conventions typographiques françaises actuelles.
Vocabulaire
Schlecht a généralement été traduit par « simple / modeste », qui est le sens courant de cet adjectif à l’époque baroque ; c’est seulement dans certains cas que nous avons retenu le sens de « mauvais / faux / moindre », plus proche du jugement de valeur, à l’évidence énoncé par l’auteur.
Nous n’avons pas toujours signalé les erreurs commises par les auteurs dans l’emploi d’un terme français dans l’original allemand.
Le terme allemand Metall a été généralement traduit par « bronze », même si, dans certains cas particuliers, nous avons opté pour l’équivalent français « métal » (Sturm, Knesebeck).
Passages illisibles
Les mots ou groupes de mots illisibles dans le manuscrit original, signalés dans la transcription allemande par un point d’interrogation entre crochets [?], sont indiqués de la même façon dans la traduction, par exemple Harrach, vue 12 (p. 466) : Hans[?] Preuker. Parfois, la traduction ne fait pas mention du doute sur l’interprétation du mot : dans Harrach vue 4 (p. 458), Körb[?] a été traduit par « paniers ». Parfois une régularisation ou une correction est proposée, encadrée des signes < > : par exemple Pitzler, vue 115 (p. 167) : prompti[?]<tude>.
Passages en français, citations, mots étrangers
Les parties de textes en français présentes dans l’original allemand ont été restituées à l’identique dans la traduction, orthographe et ponctuation comprises ; voir Neumann vues 47-50 (fol. 67r-68v) : lettre de recommandation de M. Pfütschner ; Corfey, vue 58 (p. 61) : rapport d’une sentence judiciaire. En revanche, les mots usuels isolés en français dans les textes sources ont été rectifiés si nécessaire (par exemple Harrach vues 14 (p. 468) et 16 (p. 470) : mobilirt a été traduit par « meublé ».
Les inscriptions latines ont été transcrites dans la traduction française exactement telles qu’elles apparaissent dans le texte allemand (avec les retours à la ligne, ligatures, tirets, lettres capitales, majuscules répétées aux deux premières lettres, caractères spéciaux, espacements...). Seuls les mots agglutinés n’ont pas été restitués*.* Il n’a pas été possible de fournir une traduction complète de toutes les inscriptions latines citées (et des quelques inscriptions en grec ancien). Ce n’est que dans certains cas qu’une traduction a été ajoutée dans une note, à la fin de l’inscription.
Dans les citations latines, les doubles virgules des textes allemands „ (correspondant à des tirets de césure) ont été transformées en trait d’union en français ; voir par exemple Corfey vue 18 (p. 17 ) : « felicibus annae con„» en allemand est transformé en « felicibus annae con- ».
Ajouts des éditeurs et traducteurs
En allemand comme en français, les crochets [ ] sont utilisés pour signaler des avertissements et des ajouts des éditeurs (ajout de titres pour structurer une page, de légende permettant d’identifier un dessin, d’indications spécifiques).
Pour faciliter la compréhension du texte, les traducteurs ont parfois été amenés à compléter une phrase par un ajout (verbe, groupe nominal, pronom, conjonction...). Ces ajouts sont encadrés par les signes < >.
Auteurs : Hendrik Ziegler et Alexandra Pioch
The Digital Edition described here was conceived and realized for the ARCHITRAVE (Art and Architecture in Paris and Versailles in Accounts by Baroque-Era German Travellers) project comprising the following four partner institutions:
- Philipps-Universität Marburg (UMR)
- Niedersächsische Staats- und Universitätsbibliothek Göttingen (SUB Göttingen)
- Centre de recherche du château de Versailles (CRCV)
- Centre allemand d’histoire de l’art Paris (DFK Paris)
ARCHITRAVE is a FRAL-2016 programme, financed by the Deutsche Forschungsgemeinschaft (DFG) and the Agence nationale de la recherche (ANR).
This document contains the ARCHITRAVE encoding guidelines based on XML and following the TEI P5 encoding guidelines. This digital edition is composed of six sources kept in German public archives and libraries: one printed document and five manuscripts. These are the only known original versions of the texts (the manuscript for the printed document is irretrievable). All texts were written predominantly in German from the Baroque era. The authors also often used French and Latin and at times, Italian, Dutch and Spanish. They analyse and appraise French art and architecture in the late seventeenth and the early eighteenth centuries.
The corpora is composed of letters (Sturm and Neumann), diaries (Harrach and Corfey) and prose (Knesebeck and Pitzler). Only the Knesebeck text is published in its entirety, while the other five texts have been published in part, with a focus on extracts concerning Paris and Versailles.
About this document
This document presents all the tags used in the ARCHITRAVE digital edition. It explains phenomena found in the six sources and why and how it was decided to encode them. It does not replace the official TEI Guidelines developed and maintained by the Text Encoding Initiative (TEI) consortium.
Basic encoding
The choice of TEI P5
The TEI P5 Guidelines can be considered a little light for handling some forms of writing, especially letters. However, it was decided to follow these guidelines in order to assure permanence and the possibility to exchange data. Therefore, no other referential or non-standard elements will be found here.
A single XML (Extensible Markup Language) document has been created for each manuscript and its translation. The three indexes — persons, places, works (also called “registers”) — have been created in three distinctive tables using Google Sheets and have been extracted via XQuery into three XML documents.
Encoding principles
The ARCHITRAVE digital edition uses XML (Extensible Markup Language). The XML language comprises rules and tags to structure data within a document, allowing the addition of personalised elements since it is linked to a schema, which defines its grammar.
Tag
A tag is a markup construct that begins with < and ends with >.
Example:
<placeName>Paris</placeName>
The opening tag <element>
must be followed by a closing tag </element>. Those tags respect the
strict rules of nesting. Example:
<div>
<placeName>Paris</placeName>
</div>
Another type of tag exists, which indicates a point in the text where
something happens such as the beginning of a line or page. This is an
empty element, meaning it is composed of only one part with the "/" as a
suffix and does not frame any text content. Example: <pb/>
Element, attribute and value
The tag is named “element”. Each element name is defined by the
standard, i.e. the TEI. It can contain several properties called
“attributes”, which are associated with a value. Each property is placed
inside the opening tag following this pattern: <element attribute="value" attribute="value">text</element>. Each attribute is
separated by a space. The attribute value is always between quotes.
The value of the attribute is written according to the following rules:
- If the value is only one word, the entire word is spelled in lower
case such as
<div type="text">. - If the value is composed of several words joined together, one must
apply the Lower Camel Case convention, which means that the first word
is spelled in lowercase while the first letter of the following word
is in uppercase and the rest in lowercase. For example:
<placeName type="city" subtype="passingBy">. - Where the value starts with a number, then the word uses only
lowercase, as in
<gap reason="illegible" extent="1word"/>.
Establishment of the texts
The following are the various steps of the Digital Edition:
- Digitization of the original documents (manuscript or printed work).
- Transcription of the original documents by the editorial team in a Word document, with anticipation of encoding. It was decided to transcribe manually rather than use an OCR because of the complexity of the writing and constant changes in typography, sometimes even within a word.
- Translation into French of the six texts.
- Reading and validation of the transcriptions/translations by the scientific team.
- Converting the Word documents into files following the XML-TEI format with the automatic encoding supplied by the unzip of the ".docx".
- Cleaning of the files with the XSLT stylesheet for conversion into TEI P5 within the Oxygen XML editor and through the use of regular expressions.
- Loading the files into TextGridLab: checking the first layer of encoding and proceeding with the different layers of encoding.
- Checking and validating of the encoding by the TEI expert in charge.
- Checking and validating of the encoded files by the technical team in Göttingen.
Encoding environment
The editions are encoded and published within the TextGrid environment developed by the University of Göttingen. Answering an increasing demand for digital and collective research features in the humanities, TextGrid has, since its start in 2006, established the infrastructure for a respective virtual research environment. In continuous exchange with the scientific community, TextGrid has developed a variety of tools and services available for free download in a stable version. Together with the TextGrid Repository, the virtual research environment TextGrid offers scholars in the humanities sustainable editing, storing and publishing of their data in a thoroughly tested and safe environment. For further information on TextGrid, see: "TextGrid: A Project and its History": https://textgrid.de/en/projekt.
TextGrid can embed the Oxygen XML Editor which is a complete XML development environment that includes all necessary tools for working with a wide range of XML standards and technologies.
Sources encoding
The TEI document is built on a mandatory structure composed of two main
parts: the metadata and the text. The former is contained in the
<teiHeader> and the latter is framed by the <text>. The
transcriptions and the translations themselves are contained in the
<body> element, which is structured thanks to a <div> element. The
<front> and the <back> have not been used in the project.
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Title</title>
</titleStmt>
<publicationStmt>
<p>Publication Information</p>
</publicationStmt>
<sourceDesc>
<p>Information about the source</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<body>
<div>Some text here.</div>
</body>
</text>
</TEI>
The teiHeader
Overview
Any text in TEI format is made up of a TEI header followed by the main text. The header contains information essential for identifying the document.
This header can consist of a few lines only: the electronic title, the electronic editor and a brief description of the original source. In our editions, this data is completed by information on the original source, describing the method for electronic editing. The largest number of details is required to spread and exchange the electronic files. Experience showed that the more detailed the header is, the more referenced the file is, meaning it can be used more effectively.
The basic header must have the following structure:
<teiHeader>
<fileDesc>
<titleStmt>
<title>...</title>
</titleStmt>
<publicationStmt>
<authority>...</authority>
</publicationStmt>
<sourceDesc>
<p>...</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<fileDesc> is a file description containing a full bibliographic
description of an electronic file, with the electronic title, including
the people responsible for its edition and publishing, and the
bibliographic description of the original work.
We added 2 further parts, which are:
<encodingDesc>for the relationship between the electronic text and the source.<profileDesc>for a description of non-bibliographic aspects of the text.
Bibliographic description of the file: <fileDesc>
The bibliographic description of the file begins with the electronic title and the identity of the persons responsible for its intellectual content. The source, from which the file was generated, then undergoes bibliographic description.
The element <titleStmt> (title statement) contains the following
aspects:
<title>refers to the electronic title of the work, decided by the editorial team.<funder>specifies the name of institutions and organisations responsible for the project funding.<respStmt>(statement of responsibility) gives the name of the head of the electronic collection, and of those in charge of the edition. This element is repeated for each responsibility.
The element <editionStmt> (edition statement) contains the following
editorial elements:
<edition>indicates the editor of the present electronic edition, adding the date and URL of the website thanks to the tags<date>and<ref>.
The element <extent> indicates the text’s physical size (number of
kilobytes of the file).
The element <publicationStmt> (publication statement) contains
information on organisations/institutions responsible for the
publishing.
-
<authority> indicates the name of organisations/institutions responsible for the electronic work. This element is repeated for each institution.This tag contains the following sub elements:
<address>indicates the organisation’s address.<ref>gives the URL of the institution’s website.
Example:
<authority>
<ref target="https://chateauversailles-recherche.fr/">Centre de recherche du château de Versailles</ref>
<address>
<addrLine>Grand Commun</addrLine>
<addrLine>1, rue de l’Indépendance américaine</addrLine>
<addrLine>RP 834</addrLine>
<addrLine>78008 Versailles Cedex</addrLine>
<addrLine>France</addrLine>
</address>
</authority>
<availability>describes the legal distribution restrictions (licence).
The <sourceDesc> (source description) element is a mandatory part of
the header: it registers all information on the original source. It
contains the element <msDesc> (manuscript description). Though it
originally concerns the description of manuscripts, we also used this
tag for Sturm, a printed book. This element is commonly used to describe
ancient printed books when a great number of characteristics match those
of the manuscripts.
<msDesc> contains:
<msIdentifier>(manuscript identifier) indicates where to find the source: conservation site, identifier, country and city.
Here is an example concerning the Neumann text:
<msIdentifier xml:id="Bausachen_335_I">
<country xml:lang="de">Deutschland</country>
<settlement xml:lang="de">Würzburg</settlement>
<institution xml:lang="de">Staatsarchiv Würzburg</institution>
<idno>Bausachen 335/I</idno>
</msIdentifier>
The element <idno> indicates the catalogue number of the work within
the collection of the conservation institution.
<msContents>(manuscript contents) describes the intellectual content of a text. This element contains<msItem>(manuscript item), which contains other elements such as the title<title>, the author<author>, the date of the document<docDate>as well as a descriptive note on the content<note>.
Example:
<msContents>
<msItem>
<title xml:lang="de">Briefe Balthasar Neumanns seiner Reise nach Frankreich 1723</title>
<author xml:id="Neumann" xml:lang="de">Johann Balthasar Neumann</author>
<docDate>
<date from="1723-01-11" to="1723-04-14">11. Januar bis 14. April 1723</date>
</docDate>
<note xml:lang="de">In den Briefen gibt Balthasar Neumann Rechenschaft von seiner Anreise über Mannheim,
Straßburg, Zabern, Lunéville und Nancy nach Paris.[...]</note>
</msItem>
</msContents>
This is slightly different for the Sturm text, the only printed text of
our corpus. Instead of the tag <msItem>, we use <biblStruct>
(structured bibliographic citation), which contains the sub-element
<monogr> (monographic level). The latter contains the bibliographic
elements <title>, <author>, and <imprint>, which itself contains
<pubPlace>, <publisher>, <date>. Finally, we find in
<biblStruct> a note on the document content followed by another on the
document history.
Example:
<biblStruct>
<monogr>
<author xml:id="Sturm" xml:lang="de">Leonhard Christoph Sturm</author>
<title xml:lang="de">Leonhard Christoph Sturms Durch einen grossen Theil von
Teutschland und den Niederlanden biß nach Pariß gemachete Architectonische Reise-
Anmerckungen / Zu der Vollständigen Goldmannischen Bau-Kunst VIten Theil als ein
Anhang gethan / Damit So viel des Auctoris Vermögen stehet / nichts an der Vollständigkeit
des Wercks ermangle. Cum Gratia Privilegio Sacrae Caesareae Majestatis. Augspurg / In
Verlegung Jeremiae Wolffen, Kunsthändlers / Daselbst gedruckt bey Peter Detlefssen. Anno
M DC XIX.</title>
<imprint>
<pubPlace>Augsburg</pubPlace>
<publisher xml:id="Wolffen">J. Wolffen</publisher>
<date when="1719">1719</date>
<note xml:lang="de">Es handelt sich um ein Buch im Folio-Format mit einer
durchschnittlichen Blattgröße von 33 x 20 cm. Es umfasst 144 in Frakturschrift gedruckte
Textseiten und 52 teilweise aufklappbare Kupferstichtafeln (nummeriert von A bis D vor dem
Textteil und von I bis XLVIII im Anschluss an den Textteil).[...]</note>
<note type="history">Die schließlich 1719 publizierten Architectonischen Reise-
Anmerckungen sind aus der Kompilation unterschiedlicher Reisenotizen und Zeichnungen entstanden:[...]</note>
</imprint>
</monogr>
</biblStruct>
Concerning the manuscripts, a certain number of sub elements is used:
<physDesc>(physical description) contains the physical description of the source thanks to two main elements:<objectDesc>, contains the elements:<supportDesc>(support description) groups elements describing the physical support for the written part of a manuscript.<foliation>for a detailed description of the pagination.
<handDesc>contains as many<handNote>as there are hands to describe.
<history>, for a basic description of the document history in a<p>element, with potential tags<origDate>to indicate the date of the first known version and<origPlace>the place where it was originally written.
Example:
<physDesc>
<objectDesc>
<supportDesc>
<foliation corresp="#Neumann">
<p xml:lang="de">Die Foliozählung des Archivs ist meist unten mittig auf der Vorderseite eines jeden
Blattes aufgestempelt</p>
</foliation>
</supportDesc>
</objectDesc>
<handDesc>
<handNote corresp="#Neumann" medium="blackInk" scope="major" scribe="author">
<p xml:lang="de">Neumann verwendete zwei unterschiedlich große Briefbögen.[...]</p>
</handNote>
<handNote medium="blackInk" scope="minor" scribe="archivist" xml:id="Archivist"/>
</handDesc>
</physDesc>
<history>
<p xml:lang="de">Von der kunsthistorischen Forschung sind die Briefe Balthasar Neumanns seiner Reise nach
<origPlace>Frankreich</origPlace>
<origDate when="1723">1723</origDate> seit Langem als aussagekräftige Quelle erkannt
und herangezogen worden (s. Keller 1896).[...]
</p>
</history>
Encoding description: <encodingDesc>
The encoding description clarifies the methods and main editorial principles, which facilitated the text transcription and the file creation.
- The element
<projectDesc>(project description) contains a short description of the electronic project in a tag<p>. - The element
<samplingDecl>(sampling declaration) contains a description of the reasoning and methods used for text sampling within our corpus in a tag<p>. - The element
<editorialDecl>(editorial declaration) contains the encoding editorial practice in a tag<p>.
Non-bibliographic description: <profileDesc> (text-profile description)
This part contains non-bibliographic information to describe a document.
We only use the element <langUsage> to specify the language or
languages used. It is combined with the element <language>: the
identification is revealed by the attribute @ident with the language
code. The standard code classification corresponds to the ISO
639 codes.
Example:
<profileDesc>
<langUsage>
<language ident="de">German</language>
<language ident="la">Latin</language>
<language ident="fr">French</language>
<language ident="it">Italian</language>
<language ident="nl">Dutch</language>
<language ident="es">Spanish</language>
</langUsage>
</profileDesc>
The body
The element <text> is a mandatory container for the textual content.
It bears a mandatory @xml:lang attribute whose value is "de" for the
German texts and "fr" for the French translations, in agreement with the
IEFT BCP 47 and
compliant with the ISO 639
standard.
Example:
<text xml:lang="de">
Or
<text xml:lang="fr">
It is followed by <body>, which is the only sub-element of <text>.
The <body> contains the sub-elements <div> where the different text
levels are transcribed. In some cases, there is only one sub-element
<div> with an attribute @type whose value is text; in other cases
there are several <div> elements with different attribute @type
values, depending on the text structure.
Here is an example from Neumann with several <div>:
<div type="letter">...</div>
For the manuscripts comprising letters or the diaries with specific
entries: another level of division is used, with the tag <div>. It can
be typed with only two values.
Values for @type:
- diaryEntry
- letter
For the letters and diaries, a @when attribute is used to give the date
of the entries in ISO 8601
format: yyyy-mm-dd.
Here is an example from Harrach to explain a diary case:
<text xml:lang="de">
<body>
<div type="text">
<div type="diaryEntry" when="1698-10-23">
<p>...text...</p>
</div>
</div>
</body>
</text>
It is possible to give a title to a text division when appropriate. In
this case, <head> can be used. However, it can only be at the very
beginning of the division and only once. <p> and <label> are used to
encode the smaller divisions within the texts.
<div type="text">
<head rend="center">
<lb/>
<hi rend="latin">Paris den
<date when="1685-07-14">4/14 July 1685</date>.
</hi>
</head>
text
</div>
Elements common to all the manuscripts
Paragraphs: <p>
Entities to identify paragraphs.
Sub-titles within paragraphs are tagged as <label>:
<p>
<lb/>
<label>
<rs ref="wrk:textgrid:3pfbd" type="artwork">
<hi rend="latin">Henrici IV. Statua Equestris</hi>
</rs>.
</label>...some text...
</p>
<p>
<lb/>
<label>Der
<placeName ref="plc:textgrid:3pfmk" type="place">Kirche
<hi rend="latin">des grands Jesuites</hi>
</placeName>
</label>
</p>
Anonymous block: <ab>
For Corfey and Neumann, where paragraphs are missing, an arbitrary
division was made thanks to <ab>. It can have two values for the
attribute @type:
- day
- theme
When the author gives a date, we use it to structure the text. In such
cases, the @type used is "day". When no date is given, the @type "theme"
can be used to identify a part of the text.
<ab type="day"><date when="1698-06-21">den 21 iunÿ</date> seint wir...</ab>
<ab type="theme"><lb/>Nach dem <placeName type="place" ref="plc:textgrid:3pfpn">pont Royal</placeName> ist...</ab>
Line beginning: <lb/>
To mark the beginning of a new line, every <lb/> is placed at the
start of a line with no space after the tag and before the following
word. It is used inside the structural tags <p> or <div>:
<p>
<lb/>
<placeName type="city" ref="plc:textgrid:3pg0g">Paris</placeName> ist des ganzen Königreichs...
</p>
Or
<div type="letter" n="13">
<head>
<lb/>
<hi rend="latin">XIII.</hi>
</head>
<opener>
<salute>
<lb/>Mein Herr!
</salute>
</opener>
<p>
<lb/>OB mir wohl nicht unbekant ist, ...some text...
</p>
</div>
How to deal with the hyphenation thanks to the line beginning tag (</lb>)
In order to be able to search inside the text, the terms broken between
two lines have been marked. They are identified thanks to an attribute
inside the tag <lb/> splitting the word. This always contains the
attribute @break with the value "no" and the attribute @type to indicate
the way the hyphen is written by the author.
Values for @type:
- none
- doubleHyphen
- singleHyphen
Example Knesebeck view 25:

<lb/>Dÿck</hi></persName>, <persName ref="psn:textgrid:3q1kj" type="historical"><hi rend="latin">Hondhost</hi></persName>,
<persName ref="psn:textgrid:3pgdq" type="historical"><hi rend="latin">Rubens</hi></persName> und
<persName ref="psn:textgrid:3q1jn" type="historical"><hi rend="latin">Jor-
<lb break="no" type="singleHyphen"/>dan</hi></persName>, und mit vielen Golde her,,
Page beginning, form works and facsimiles: <pb/> and <fw/>
<pb/> appears at the start of each page with the attribute @n
indicating the value of the page. The pagination of several of the
sources was quite difficult. There are pages with the same number, some
missing pages or pages with a number that was later added by the author.
Since we could not work with pages bearing the same number as we were
using these numbers for the navigation system, we decided to create a
new pagination, although this interrupts the integrity of the work. The
value of the attribute @n is a continuous numbering. It is coupled with
an automatically added URI for each facsimile picture, contained in the
attribute @facs.
The form work tag (<fw>) is also used also for page numbers to
differentiate between multiple hands and the location on the page thanks
to the @place. The @hand is used to identify the person who has written
the number, for example the author or the archivist. This person is
referenced in the teiHeader by an @xml:id (first and last name initials)
in order to be linked to its occurrences in the text via the #
contained in the @resp. The added part of the page number has to be
encoded with the element <supplied>. The attribute @resp references
every page number created by a member of the team with this element
where none is given in the manuscript, and to justify the identification
of the hand. We also added an attribute @cert to clarify our position in
this regard.
Values for @place:
- topLeft
- topRight
- topCenter
- botLeft
- botRight
- botCenter
- leftCenter
- none
Example Knesebeck view 9:
<pb n="009" resp="#Architrave"/>
<fw type="pageNum" place="topRight" resp="#Knesebeck?">3
<supplied cert="high" reason="regularized" resp="#AJ">r</supplied>
</fw>
<fw type="pageNum" place="botCenter" resp="#archivist?">3
<supplied cert="high" reason="regularized" resp="#AJ">r</supplied>
</fw>

The sources were not encoded in their entirety. A selection was made to focus mainly on the itineraries through France. Therefore, the pagination is not always consistent. Moreover, the pagination of the original sources is also not always consistent. In some cases, we were not always able to determine whether a page was missing or if it even existed. Thus we did not encode missing pages, only the pages for which we have the digital pictures. For more information on the selection of the passages we chose to edit, please consult the introductive texts to each edition by clicking on "Edition / Édition" > "Quellenkorpus / Corpus des sources" and choosing the respective author. You will find detailed information under the section entitled "Zur Quelle / La source".
Paragraphs spanning several pages
Paragraphs spanning several pages are divided for ease of viewing. This
is done using the attributes @xml:id, @prev and @next. Each paragraph is
therefore assigned an xml:id. This is carried out as follows: p1. The p
refers to paragraph and the number to its rank. When a paragraph spans
several pages, the @xml:id is p1 with a letter suffix: p1a, p1b and p1c.
<p xml:id="p30a" next="#p30b">
<p xml:id="p30b" prev="#p30a" next="#p30c">
<p xml:id="p30c" prev="#p30b" next="#p30d">
<p xml:id="p30d" prev="#p30c">
Graphic divisions of the text: <metamark/>
The authors of the sources sometimes used lines to mark the distinction
between two divisions of text, however these lines do not belong to the
textual division. The choice between
<milestone>
and
<metamark>
was somehow a difficult one. Digital edition projects mostly use the
first tag. However, even if the drawn lines show an obvious intent to
divide the text, they are also used to underline a missing word, which
the author intended to fill in later or to help organise the layout of
the page. Since the textual divisions were already outlined, we decided
to use a rather graphical tag to encode those phenomena. We should also
add that the mandatory attribute @unit for the <milestone>, implying a
rather strong meaning of textual division, was not used, as we do not
wish to emphasise this aspect as regards the drawn lines present in our
sources.
<metamark> is used with the attribute @rend, whose values are:
- verticalLine
- horizontalLine
- dotedLine
- doubleHorizontalLine
- horizontal
Example Corfey view 15:
<lb/>
<quote xml:id="q36" xml:lang="la">
<hi rend="latin">genua emendata MDCLXXXIV</hi>
</quote>.
<metamark rend="horizontalLine"/>

Example Pitzler view 10:
<figure>
<figDesc>[Ansichten von Kaminen]</figDesc>
<figDesc>[Detailskizze von einem Kamin]</figDesc>
<p>
<hi rend="latin">profil</hi>
</p>
</figure>
<metamark rend="verticalLine"/>
Example Pitzler view 10:
<figure>
<p>
<lb/>So in einem Zimmer der Fußboden
<lb/>von Holz, kan vor dem
<hi rend="latin">camin</hi>
<lb/>eine steinerne Plate gelegt werden
<lb/>auch nach gelegeheit zierlich seùen
</p>
<figDesc>[Grundrisse/Skizzen von zwei Kaminen]</figDesc>
<p>
<lb/>
<hi rend="latin">camin</hi>
</p>
</figure>
<lb/>
<metamark rend="horizontalLine"/>

Sometimes the authors draw short lines along the text, to finish a line and create a separation before a quotation or at the end of a quotation for example. We used the character: _
Example Corfey view 16:
<lb/>
<quote xml:id="q39" xml:lang="la">
<hi rend="latin">
<foreign xml:lang="fr">du regne de Lovis XIV _ de la prevôté de Messire _ alexandre
<lb/>de Sueve _ prevôt des Marchands etc _ Ce present pont
<lb/>a été bâti
</foreign> _ aediles recreant Submersum flumine
<hi rend="below">pontem</hi> _
</hi>
</quote>

A hyphen is also used in some cases by authors in a poem or in an inscription to mark the end of a verse.
To transcribe double dashes, we used the = special character.
Example Corfey view 17:
<hi rend="latin">quod trajectum ad Mosam _ XIII diebus coepit = praefectus
<lb/>et aediles _ poni c c _ anno domini MDCLXXIII
</hi>

Changes in the manuscript: <del> and <add>
Five of the six sources are manuscripts in which we find deletions and
additions. Where someone other than the author has carried out a
deletion or addition, this is specified by the use of the attribute
@hand. The person is added inside the <handNote> and is also
referenced in the <teiHeader>.
Example Harrach view 13:
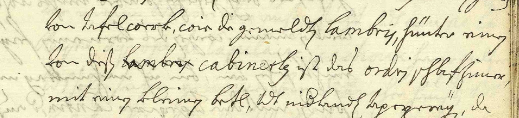
<lb/>von disen
<del hand="#Harrach" rend="strikethrough">
<hi rend="latin">lambris</hi>
</del>
<hi rend="latin">cabinetlen</hi> ist das
<hi rend="latin">ordry</hi> schlafzimer,
Values for @rend:
- strikethrough
- overwritten
The addition also has the @hand attribute denoting the deletion and a
@place attribute.
Values for @place:
- above
- below
- bottom
- top
- inline
- across
- marginLeft
- marginRight
- marginTop
- marginBottom
- nextPage
- prevPage
The <add> tag is used for all additions made with a clear sign or
anchor in the text and inside the layout of the page. Additions, which
do not follow these rules, are encoded with the <note> tag. See below
for more information on notes.
Example Knesebeck view 39:
<lb/>des
<persName ref="psn:textgrid:3q1jz" type="historical">königs Lud: XII.</persName>
<add place="above" xml:id="addp79_1a">
<hi rend="superscript">+)</hi>
</add> auffgerichteten
<hi rend="latin">Arcaden</hi>
[...]
<add place="bottom" hand="#Knesebeck"> +) und Anne de Bretagne</add>

Where the text of the addition and the sign or anchor are on two different pages, a link is made between the two.
Example Corfey views 5 and 6:
On one side, we have:
<pb n="5"/>
<add hand="#Corfey" place="nextPage" type="asterisk" xml:id="addab10_1a">
<ref target="#addab10_1b">
<hi rend="superscript">x</hi>
</ref>
</add>

On the other side:
<pb n="6"/>
[...]
<add hand="#Corfey" place="prevPage" type="asterisk" xml:id="addab10_1b">
<lb/><ref target="#addab10_1a"><hi rend="center">x</hi></ref>sonsten ist zu <placeName type="city">brussel</placeName>
noch Remarquir<add>en</add>s
<lb/>wert daß die hunde alda nicht allein
<lb/>vor die chaisen der Kinder, sondern
<lb/>so gahr <del rend="strikethrough" hand="Corfey">fur</del> vor absonderliche Karr<add>en</add>
<lb/>gespannet werden um getreit nach
<lb/>den Muhlen u<add>n</add>d gartengewachs nach
<lb/>der statt zu fuhren, u<add>n</add>d ist zu ver
<lb/>wundern das 4 hunde zuweilen Mehr
<lb/>als 1 pferd ziehen konnen
</add>

If a passage is blackened rather than struck through, making the text
illegible, it was encoded with a <del> combined with <gap>,
<unclear> or <supplied>.
Example Corfey view 135:
<lb/>con prb eccle Massiliens
<del hand="#Corfey" rend="strikethrough">
<gap cert="high" extent="1word" reason="illegible" resp="#AJ"/>
</del>
<lb/>anno XV eptus Sui d. ann VIII id OCB

The <subst> tag comprises a <del> and an <add> when they are
associated. In this case, the attribute @hand is placed on the <subst>
tag rather than on the <del> or the <add>, such as in the example
below.
Example Harrach view 12:
<subst hand="#Harrach">
<del rend="overwritten">freù</del>
<add place="across">donners</add>
</subst> tag den 3
<subst hand="#Harrach">
<del rend="overwritten">0</del>
<add place="across">1</add>
</subst>

Spaces inside the texts: <space>
Some blank spaces are significant inside the manuscript. They are
encoded with the tag <space>. The tag is associated with three
attributes: @extent, @dim (which allows only two values: "horizontal"
and "vertical") and @rend (with a value "blank" or "line"). The @extent
value varies according to the situation. For the @dim, we followed the
TEI Guidelines to specify irregular shapes. The value refers to the more
important of the two dimensions (horizontal or vertical). For left-right
scripts, the space is predominantly qualified as "vertical".
In general, we did not encode blank spaces in the French version.
Values for @dim:
- horizontal
- vertical
Values for @extent:
- 1word
- 2word
Values for @rend:
- blank
- line
A significant blank space can also be the result of a missing word or a
forgotten addition the author wanted to make later. For those cases, the
tag <space> is used too. The same attributes are used while adding the
@resp to distinguish the person in charge of identifying the significant
space. <space> and <gap> are distinct: the former is a blank space
found in the text as a deliberate gesture of the author, whereas the
latter refers to a part of the text that can not be transcribed.
Example Harrach view 55:
<space dim="horizontal" extent="1word" rend="blank" resp="#MM"/>
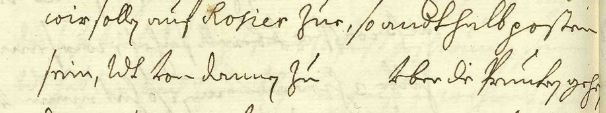
How to make a proposition: <supplied>
Proposals to fill a blank space have sometimes been made, thanks to the
<supplied> tag with the attributes @reason and @resp. An attribute
@cert was added where required. The supplied tag is also used in case of
damaged and unreadable extracts that one would like to interpret.
Values for @reason:
- illegible
- regularized
- translation
- unprinted
Example Sturm view 134:
<item>
<hi rend="latin">
<supplied cert="high" reason="illegible" resp="#MM">b.
<placeName ref="plc:textgrid:3r30x" type="place">Bosquet du Dauphin</placeName>
</supplied>
</hi>
</item>

Difficulties in reading: <unclear> and <gap/>
When a word is illegible, the tags <unclear> or <gap> were used.
<unclear> is used when the extracts are difficult to read or to
transcribe with certainty. It is associated with the attributes @reason,
@resp and @cert.
Values for @reason:
- illegible
Values for @cert:
- unknown
- low
- medium
- high
Example Harrach view 12:
<unclear cert="unknown" reason="illegible" resp="#MM">hans</unclear>
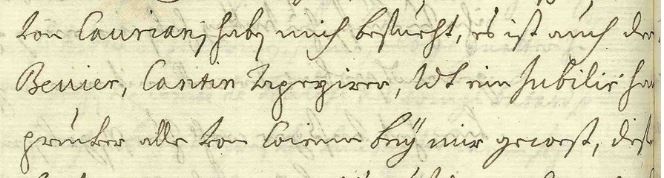
We use the tag <gap> for illegible passages for which an
interpretation is impossible. It takes the attribute @extent to give an
appreciation of the length, as <gap> is an empty tag, since it is
incapable of giving a clear idea of its impact on the text, unlike the
tag <unclear>. It is also working with the attribute @reason with the
same possible values as for <unclear>.
Values for @reason:
- illegible
Values for @extent:
- 1word
- 2words
Example Corfey view 77:

— 1
<del hand="#Corfey" rend="strikethrough">
<gap cert="high" extent="1word" reason="illegible" resp="#FD"/>
</del> biß 1
<num rend="horizontal" type="fraction" value="0.5">1/2</num> fues.
Example Corfey view 163:
<lb/>Benefactori
<unclear cert="unknown" reason="illegible" resp="#FD">anp</unclear> amplissimo

Example Corfey view 155:
<lb/>Veladus Maximï
<del hand="#Corfey" rend="strikethrough">
<gap cert="high" extent="1word" reason="illegible" resp="#AJ"/>
</del> filij

Example Corfey view 115:
<space dim="horizontal" extent="2words" rend="blank"/> VOLKANO

Sometimes the editor proposes an interpretation of an illegible word. In
this case, the <gap> tag is replaced by the <supplied> tag when the
text is completely illegible or missing. It is associated with the same
attributes @reason, @resp and @cert as for the <unclear> tag. If the
text is difficult to read but still legible, we used the <unclear>
tag.
Shift of hand: <hi> and @hand
The TEI Guidelines allow qualifying changes of hands inside the text
with the help of the tag <handShift> or with the attribute @hand. We
chose to encode the change of hand through the @hand attribute on
<subst>, <del> and <add> tags. When this was not possible, we
added a <hi> tag.
The different hands encountered in the manuscripts are: the authors, secretary, archivist.
For example, in Knesebeck’s manuscript a sentence had been filled in later using a pencil.
Values for @rend:
- pencil
- ink
- pencil_retraced_in_ink
Example Knesebeck view 144:
<hi rend="pencil">Hinter derselben ist der
<rs ref="wrk:textgrid:3q7gp" type="artwork">Todt Mariæ</rs>
</hi>

Example Neumann view 8:
<note type="secretary">
<lb/>
<hi hand="#Secretary" rend="ink">
<date when="1723-01-17">17
<choice>
<abbr>Jan:</abbr>
<expan>Januar</expan>
</choice> 1723
</date>
</hi>
</note>

Spelling corrections: <supplied>
We did not normalise the historical spelling or the missing glyphs.
However, we did make corrections when necessary in order to understand a
word thanks to the <supplied> tag, always using @resp and @cert
attributes.
Example Harrach view 2:
auß we
<supplied cert="high" reason="regularized" resp="#MM">c</supplied>hslung der münz, u
<supplied cert="high" reason="regularized" resp="#MM">n</supplied>dt andern nit
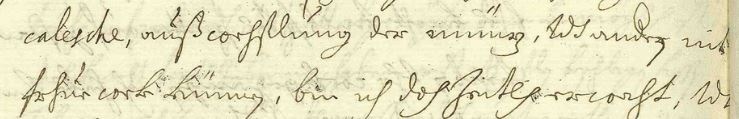
Agglutinated words and spaces between words
We did not use the <supplied> tag for the regulation of spaces since
this tag is employed for an addition made by the editor. We chose a
rather simple encoding: each term of the author’s expression is divided
and encoded with a <w> tag, which means, “word”. The first one bears
the attribute @type with the value "noSpace" and @n, which contains the
initial expression without the added spaces. We also used @join, which
can be "left", "right" or both (for the middle word when 3 words are
agglutinated) to indicate how the word is linked with the other part of
the expression. We decided not to use the @resp and @cert attributes in
this case in order to make the code easier for the encoders to read.
Example :
<lb/>lenderen
<w join="right" n="zuthuen" type="noSpace">zu</w>
<w join="left">thuen</w>

Use of special characters
For the special characters in our texts, we use unicode symbols. Here is the list of these characters:
- ⨀ (U+2A00) for the gilt colour symbol
- ☽ (U+263D) for the silvery colour symbol
- ⸗ (U+2E17) for the double hyphen symbol
- ☧ (U+2627) for the Christ monogram
- ⊕ (U+2295) used by Pitzler to mention a paging
- " (U+2033) for the double prime
- ̊ (U+030A) for a diacritic sign in Harrach
Abbreviations: <choice>, <abbr> and <expan>
We decided to develop every abbreviation contained in the texts. If the abbreviation has a French or Latin origin, it will be expanded in German. For this reason, oct. is expanded to "October" and not "octobre" or "octobris".
Example Harrach view 2:
<date when="1698-10-20">Montag, den 20
<hi rend="latin">
<choice cert="high" resp="#FD">
<abbr>Oct</abbr>
<expan>October</expan>
</choice>
</hi>
</date>
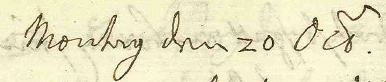
However, the words finishing with “-en” are not considered abbreviations. This issue stems from an unclear writing. They have not been encoded but simply transcribed in full, in order to lighten the encoding.
Foreign language: <foreign>
The two main languages are French and German: they are specified in the
<profilDesc> of the teiHeader as well as the value attribute at the
root tag <text> (example: <text xml:lang="de">). To highlight parts
of the text written in a language other than the two main languages, the
attribute xml:lang is used on <p>, <hi> and on <quote>. If the
change of language is independent of an existing tag, then the
<foreign> tag is used with the @xml:lang as attribute.
As defined by the TEI consortium, the xml:lang is a standard format. We decided to follow the ISO 639.
Values for @xml:lang:
- fr for French
- de for German
- it for Italian
- nl for Dutch
- es for Spanish
- la for Latin
- en for English
Quotations: <quote>
All the quotations and epigraphs are encoded with the <quote> tag. It
is the only encoding layer applied on this type of information.
The <quote> is often in another language: the attribute @xml:lang is
then specified. An attribute @rend on a <hi> tag is used to indicate
the quote’s position on the page.
Values for @rend:
- left
- right
- center
Example Corfey view 108:
<lb/>
<quote xml:id="q150" xml:lang="la">
<hi rend="latin">
<hi rend="center">VXORI
<lb/>OPTIMAE
<lb/>T. FLAVIVS
<lb/>AVG. LIB.
<lb/>ASIATICVS.
</hi>
</hi>
</quote>

Highlighted text: <hi>
According to the TEI Guidelines, the tag <hi> is used to embody a
graphical change between the tagged part of the text and its
surroundings, such as a graphical change in script. The attribute @rend
is associated with it.
Values for @rend:
- underline
- superscript
- latin (in opposition to a cursive script, default state of the text)
- italic (in order to follow the modern editorial convention for French texts)
- pencil
- left
- right
- center
- above
- below
- dotedLetter
- smallCaps
- ink
- pencil_retraced_in_ink
Example Corfey view 134:
<hi rend="dottedLetter">PLEBS</hi> narbonensis
<lb/>
<hi rend="dottedLetter">N</hi>uminis augusti di
<lb/>cavit
<unclear cert="unknown" reason="illegible" resp="#FD">
<hi rend="dottedLetter">ARAM</hi>
[...]
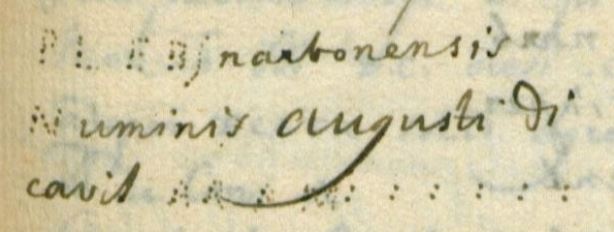
Example Knesebeck view 7:
<hi rend="latin">Von
<placeName n="1" ref="plc:textgrid:3pfv7" subtype="passingBy" type="city">Braunschweig</placeName> ist die erste Post nach
<placeName n="2" ref="plc:textgrid:3pxdb" subtype="passingBy" type="city">Peina</placeName>
</hi>

Example Sturm view 5:
<hi rend="latin">Excell.</hi> der Herr Graff von N. erwählet hat seinen Sohn,

Lists: <list> and <item>
It was decided to use a light structure to encode lists with only two
tags, <list> and <item>, and no attributes. The text contained
inside a <figure> tag can not be encoded as <list>. In the texts, a
list is characterised as short: each item comprises only a few lines.
Moreover, the layout is different from the rest of the text.
Example Sturm view 23:
<list xml:id="l1">
<item>Erstlich: Daß die drey Schlitze durchgehends an einem Gebäude gleiche
<lb/>weit voneinander stehen.
</item>
<item>Zweytens: Daß sie an der Höhe gegen der Breite sollen seyn wie drey gegen
<lb/>zwey.
</item>
<item>Drittens: Daß die Zwischen⸗Tieffe, das ist der ledige Platz, so zwischen
<lb/>zwey Drey⸗Schlitzen bleibet, ein
<hi rend="latin">accurat Quadrat</hi> sey.
</item>
<item>Vierdtens: Daß über die Mitte der Säule just die Mitte deß Drey⸗Schlitzes
<lb/>zutreffe.
</item>
<item>Fünfftens: Daß über den Fenstern Thüren und Bilder⸗Blindten, entweder
<lb/>ein Drey⸗Schlitz, oder eine zwischen Tieffe mit der Mitte <hi rend="latin">accurat</hi> zutreffe.
</item>
<item>Sechstens: Daß das gantze Gebälcke just vier <hi rend="latin">Modul</hi>, oder zwey Säulen⸗
<lb break="no" type="doubleHyphen"/>Dicken hoch sey, endlich
</item>
<item>Siebendens: Daß der Borten nicht niedriger seyn soll, als der <hi rend="latin">Arcchitrav</hi>.
</item>
</list>

If part of the list is located on the page, we use the attribute @rend
on a <cb/> tag (see below) with left, center or right. In cases where
only the number has its own layout, it is encoded with the <num> tag
and the attribute @rend.
Example Knesebeck view 26:
<list xml:id="l1">
<item><hi rend="latin">a.</hi> der Sahl der algemeinen <hi rend="latin">Conferentien.</hi></item>
<item><hi rend="latin">b.</hi> gemächer des <hi rend="latin">Mediatoris.</hi></item>
<item><hi rend="latin">c. deßen</hi> Gemach zu den besondern <hi rend="latin">con,,
<lb/>ferentzien.</hi></item>
<item><hi rend="latin">d.</hi> freùplätze vor der treppe,</item>
<cb rend="right"/>
<item><hi rend="latin">e. galerien.</hi></item>
<item><hi rend="latin">f.</hi> gemächer der <hi rend="latin">Alliirten</hi> Ab,,
<lb break="no" type="doubleHyphen"/>gesandten,</item>
<item><hi rend="latin">g.</hi> Gemächer der frantzösischen
<lb/>Abgesandten.</item>
</list>

Fractions: <num>
Numbers are not encoded in the texts. Nevertheless fractions are encoded
using a <num> tag with an attribute @type and @value. The @type has
just one value ("fraction"), while the @value is the fraction translated
into a numerical value.
Example:
<num type="fraction" value="0,5">1/2</num>
The tag <num> for fractions is associated with the @rend attribute
"horizontal".
Columns beginning: <cb/>
The tag marks the beginning of a new column on a page containing several
columns, and is associated with the @rend attribute.
Values for @rend:
- left
- center
- right
Example Corfey view 172:
<cb rend="left"/>
<quote next="#q279b" xml:id="q279a" xml:lang="la">
<hi rend="latin">
<lb/>Sex. aemilio paullo patri
<lb/>aemiliae q. F. Regiliae Mat.
<lb/>Sex aemil
<w join="right" n="paullinofratri" type="noSpace">paullino</w>
<w join="left">fratri</w>
<lb/>C. aemil. Vestus
<lb/>suis.
<lb/>
<metamark rend="horizontalline"/>
</hi>
</quote>
<cb rend="center"/>
<quote next="#q279c" prev="#q279a" xml:id="q279b"
xml:lang="la">
<hi rend="latin">
<lb/> T. Cornelio
<lb/> T. F. Nasoni
<lb/> Tertia uxor.
<lb/>
<metamark rend="horizontalline"/>
<lb/>Mercurio
<lb/>V. s.
<lb/>priscilla.
<lb/>
<metamark rend="horizontalline"/>
</hi>
</quote>
<cb rend="right"/>
<quote prev="#q279b" xml:id="q279c" xml:lang="la">
<hi rend="latin">
<lb/>A. Cornelio
<lb/>M. F. Cano
<lb/> Tertia uxor.
<lb/>
<metamark rend="horizontalline"/>
</hi>
</quote>

Tables: <table>
The table is composed of a main tag <table> divided in <row>, which
contains the tag <cell>. The table can have one tag <head> just
after the opening tag <table>. If a cell has a role of header for the
columns or the rows, we use the attribute @role with the value "label".
Value for @role:
- label
Example Corfey view 64:
<table>
<head>le Corps de bataille 2 ligne</head>
<row>
<cell role="label">2 bourbonnois</cell>
<cell>W</cell>
<cell>W</cell>
<cell>R</cell>
<cell>R</cell>
</row>
<row>
<cell role="label">1 la Couronne</cell>
<cell>W</cell>
<cell>bl</cell>
<cell>bl</cell>
<cell>bl</cell>
</row>
<row>
<cell role="label">2 Lionnois</cell>
<cell>W</cell>
<cell>R</cell>
<cell>gru</cell>
<cell>R</cell>
</row>
<row>
<cell role="label">1 La Chastre</cell>
<cell>W</cell>
<cell>R</cell>
<cell>ge</cell>
<cell>R</cell>
</row>
</table>
Dates: <date>
Dates are encoded to date letters and itineraries when day-month-year are given. They are not encoded when only the year is given, when associated with works of art or inside quotations and inscriptions cited in the texts.
Dates are encoded as <date>. They have been normalised following the
ISO 8601 standard. Their form
is year-month-day given as value of the attribute @when. It always uses
the Gregorian calendar as reference.
Example:
<date when="1698-10-20">Montag, den 20 Oct</date>
Named entities such as persons, places and artworks: <persName>, <placeName>, <geogName> and <rs>
Name entities are not encoded when the names of places, people and works are quoted in citations or inscriptions in Latin or other languages.
The are sometimes differences between the German version (transcription)
and the French version (translation): adjectives in German are sometimes
transformed into nouns in French. For example in Harrach view 48, we
have encoded the countries "France" and "Denmark" in the French version,
but not in the German transcription since they are adjectives ("die
beede in franzosischen diensten sein" ; in French: "tous deux en mission
en" `
Persons
Every time a person, a place, a geographical feature or a work of art is
evoked, it has be encoded with <persName>, <placeName>, <geogName>
and <rs> respectively. For each one, an entry is created in an index
and receives a unique TextGridID. This reference is given as the
attribute’s value thanks to the @ref. It is built with a prefixe: "psn"
for persons, "wrk" for artworks and "plc" for places and geographical
features.
The <persName> is also associated with an attribute @type whose value
is unique: "historical". This reflects the evolution of the encoding
choices: at the beginning of the project, the tag <persName> bore
three types: "historical", "mythological" and "religious". It was later
decided to leave out the mythological and religious persons.
Example:
<persName ref="psn:textgrid:3q1jk" type="historical">duc d’Albe</persName>
The names are typed and when required, subtyped.
Value for @type:
- historical
Values for @subType:
- family
- persons: used inside a
<persName>tag to encode several persons
Examples:
- Harrach view 11:
<persName ref="psn:textgrid:3q1tw psn:textgrid:3q1tv" subtype="persons" type="historical">2 söhn</persName>
- Neumann view 91:
beù denen <persName ref="psn:textgrid:3pg7t psn:textgrid:3qwc0" subtype="persons"
type="historical"><hi rend="latin">Architectis</hi></persName>
- Neumann view 74: when a person could not be clearly identified but the editor made 2 or more propositions of identification, we used the subType "persons" and encoded several persons :
ein <hi rend="latin"><persName ref="psn:textgrid:3qwc5 psn:textgrid:3qwc8 psn:textgrid:3qwcb"
type="historical" subtype="persons">tapecier</persName>
Geographical names
The geographical features are typed.
Values for @type:
- mountain
- water
- desert
- island
Places
The places are typed and when required, subtyped.
Values for @type:
- continent
- country
- region
- district
- city
- place
Values for @subType:
- passingBy
- rooms: used to encode several rooms of a residence inside a same
<placeName>tag - residences: used to encode several residences inside a same
<placeName>tag
Examples:
<placeName ref="plc:textgrid:3ph2b" type="city" subtype="passingBy" when="1698-10-24"><hi rend="latin">Poitiers</hi></placeName>
<placeName ref="plc:textgrid:3pfsf plc:textgrid:3pfsj" subtype="rooms" type="place">2 vierekten gleichen Saalen</placeName>
<placeName ref="plc:textgrid:3pfdg plc:textgrid:3pfdn plc:textgrid:3pfdk plc:textgrid:3pfdc" subtype="residences"
type="place">vier Königlichen Pallästen</placeName>
A complementary layer of encoding has been added for some places: if a
traveller went through or visited a place, it is specified thanks to the
attribute @subtype whose value is "passingBy". An attribute @n indicates
the order of the cities passed through all along the route. If possible,
it can be associated with the attribute @when with the date of the day
in ISO 8601 format the
traveller was there. This encoding is used to visualize the itineraries
of the travellers on maps of Europe, France and Paris (see the section
Reiserverlaüfe
/ Itinéraires des
voyageurs).
However, it was decided to avoid mentioning the fictional descriptions
of places never visited.
Examples:
<placeName ref="plc:textgrid:3pfvv" type="city" subtype="passingBy" n="1" when="1698-06-18">Warendorff</placeName>
<placeName ref="plc:textgrid:3pfvk" type="city" subtype="passingBy" n="2" >Munster</placeName>
<placeName ref="plc:textgrid:3pfv9" type="city" subtype="passingBy" n="3" when="1698-06-19">Coesfeld</placeName>
We have encoded:
- 24 passingBy in Pitzler
- 46 passingBy in Harrach
- 120 passingBy in Corfey
- 67 passingBy in Knesebeck
- 48 passingBy in Neumann
Works
The <rs> is also associated with an attribute @type whose value is
unique: artwork. This reflects the evolution of the encoding choices: at
the beginning of the project, the tag <rs> bore three types:
"artwork", "book" and "technic". It was later decided to use one single
sub-type for all types of artworks (paintings, sculptures, drawings,
tapestries, engravings, books, machines and other technical devices...).
Value for @type:
- artwork
Examples:
<rs ref="wrk:textgrid:3pfbf" type="artwork"><hi rend="latin">statua</hi></rs>
Named entities across two pages
When entities span two pages, the encoding has to be adapted to simplify
viewing. The system is the same as for <p> tags. In addition to the
attributes @type and @ref, each part of the entity is encoded with an
@xml:id built with the TextGridID + "-a" for the former and "-b" for the
latter. The attributes @next for the first half and @prev for the other
half are added to point to the id of the other part.
Example Corfey views 91-92:
91:
<persName next="#textgrid3pgg2-b" ref="psn:textgrid:3pgg2" type="historical" xml:id="textgrid3pgg2-a">Madame</persName>`

92:
<ab next="#ab111c" prev="#ab111a" type="theme" xml:id="ab111b"><lb/><persName prev="#textgrid3pgg2-a" ref="psn:textgrid:3pgg2"
type="historical" xml:id="textgrid3pgg2-b">la duchesse de Bourgogne</persName>
Notes
There are two types of notes in the ARCHITRAVE digital edition.
- The ones contained in the original sources, which can have been
written by the author, the archivist or the publisher. They are
close to the
<add>tag, which is why the attributes@placeand@handare also used. They are typed "authorial".
Values for @type:
- authorial
- archivist
- editorial
- translation
- scientific
- secretary
Values for @place:
- marginLeft
- marginRight
- marginTop
- marginBottom
Example Corfey view 2:
<note place="marginLeft" type="authorial">Wilmstat.</note>

Among the project’s sources, Sturm is an exception since it is a printed source for which we can not evaluate the role of the author and the role of the editor/publisher. That is why the annotations have been typed "editorial".
Example Sturm view 80:
<note place="marginLeft" type="editorial"><hi rend="latin">Clagny</hi>.</note>

The second group of notes does not appear in the sources: they are the
notes provided by the ARCHITRAVE team. These annotations are typed and
linked to the contributor with an attribute @resp.
Values for @type:
- translation (notes made by the translators)
- scientific (annotations by the editorial team related to the edition of the manuscripts)
Example Harrach view 2:
- German version:
<note type="scientific" resp="#HZ">Harrach meint wahrscheinlich die bereits in Frankreich liegende Gemeinde
„Urrugne“, die zwischen Irun und St.-Jean-de-Luz liegt.</note>
- French version:
<note type="scientific" resp="#HZ">Harrach désigne par « Ordonno » en allemand probablement
« Urrugne », commune française située entre Irun et Saint-Jean-de-Luz.</note>
Stamps: <stamp>
The marks and wording from the stamps are marked up with the element
<stamp>.
Example Knesebeck view 3:
<stamp>
<lb/>Ex
<lb/>Bibliotheca
<lb/>Academiae
<lb/>Rostochiensis
</stamp>
Drawings: <figure> and <figDesc>
To represent any graphic element, the TEI uses the tag <figure>. A
description of the drawing written by one member of our team is
contained in the tag <figDesc>. And the author’s comment is toggled
between <p>. A named entity contained in a <figDesc> is encoded only
if the person, place or work is not mentioned previously on the page.
Example Pitzler view 3:
<figure>
<p>
<lb/>Anmerckung
<lb/>wo ein austrit wie beù <hi rend="latin">A</hi>
<lb/>gemacht werden soll, konnen
<lb/>die <hi rend="latin">sopports</hi> uf diese arten seyn
</p>
<figDesc>[Detailskizzen von Konsolsteinen]</figDesc>
</figure>
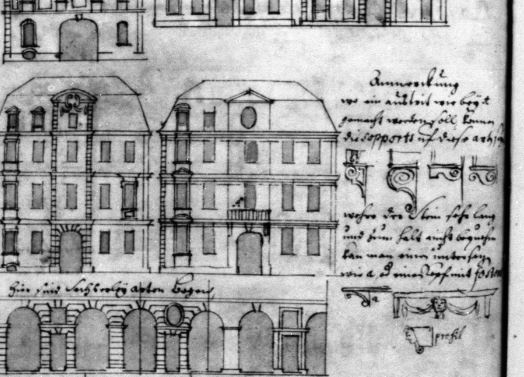
Pointers and links inside one manuscript: <ref>
Different locations inside one manuscript can be interlinked together
thanks to the tag <ref>, associated with an attribute @target, wich
points to an attribute @xml:id. The pointers are used to link a mention
of a drawing or plate and the drawing or engraving itself, mostly when
the latter is to be found at the end or at the beginning of the text. We
have created @xml:ids to set up the links.
Example:
- Knesebeck view 69:
<ref target="#knesebeck_fig.2" xml:id="knesebeck_drawing_2">grundriß zu sehen</ref>
is linked to:
- Knesebeck view 152:
<figDesc xml:id="knesebeck_fig.2"><ref target="#knesebeck_drawing_2">[2] [Lageplan von dem Collège
des Quatre-Nations in Paris]</ref></figDesc>
Specific elements for encoding letters and diaries
Letters and diaries are encoded with a specific structure.
Opener: <opener>
The preliminary part of a letter is encoded with the <opener> tag. It
can comprise the <salute> tag for the salutations.
Example Neumann view 1:
<opener>
<lb/>
<salute>Hochwürdtigster Reichs fürst Gnädigster
<lb/>fürst vndt Herr Herr.
</salute>
</opener>

Closer: <closer>
For the complementary close of the letter, we use the <closer> tag,
which groups together salutations (<salute>), the place and the date
(<dateline>) and the signature (<signed>).
Example Sturm view 9:
<closer>
<lb/>
<salute>Meines Herrn</salute>
<lb/>
<dateline>
<address>
<lb/>
<addrLine>
<placeName ref="plc:textgrid:3q1d1" type="city">Rostock</placeName>
</addrLine>
</address>
<date when="1716-08-28">den
<hi rend="latin">28. August 1716.</hi>
</date>
</dateline>
<lb/>
<lb></lb>
<signed>
<hi rend="right">Unvermögender doch gutwilliger
<lb></lb>Diener
<lb/>
<hi rend="latin">N.N.</hi>
</hi>
</signed>
</closer>

Addresses: <address> et <addrLine>
The address tag is used to encode an address. It can be found in letters
and in diary entries. Each line is also encoded as <addrLine> inside
which it is possible to encode the places and persons as specified
above. <addrLine> means a new line of an address, so <lb/> is not
used at the same time.
Example:
<address>
<addrLine>
<placeName type="city">Rostock</placeName>
</addrLine>
</address>
The encoding of translations is very similar to that of German texts
except for some details. We decided not to keep the <lb/> tags. The
encoding of the text-formatting with the <hi> tag is also excluded.
Only foreign languages such as Latin are tagged with <hi>. For this
case, the value of @rend is "italic". All encoding relating to
specificities of the German source, such as for letters added to correct
original spellings, the encoding of abbreviations, unclear words for
which the translator made choices, is of course absent from the French
texts.
The translation does not follow the line breaks of the German transcription, which reproduces the layout of the original German text, but remains as close as possible to it for the rest of the layout: the sentence breaks from one page to the other, line breaks and blanks, indentation, presentation of lists and tables, legends of drawings and sketches, arrangement of Latin quotes and inscriptions, dashes, lines and horizontal lines. The underlining has been retained only occasionally to facilitate locating and to compare the French to the German text placed opposite. However, the distinct font used in some passages in cursive script in the German texts is not reproduced in the translation.
Index encoding
The ARCHITRAVE digital editions have three indexes, one for persons, one for places and one for works of art and architectural elements described by the authors. Enrichment of indexes was carried out in three Google Sheets, which have been transformed in three XML-TEI files.
For detailed information about the content of indexes, see index guidelines: Informations sur les index / Registerrichtlinien.
Index of persons
The XML-TEI file contains a simplified teiHeader with the edition and
publication information as for the XML-TEI files of the 12 editions. The
index is in the <body> tag inside <text>. It is organised in list
form inside the tag <listPerson>, which contains as many <person>
tags as we have different persons in our texts. The tag <person> is
typed with the two values "identified" or "unidentified". It uses an
@xml:id whose value is unique for each person and is composed of
“textgrid:” followed by a mix of five letters and numbers. This @xml:id
links each occurrence of the person in our texts to their record in the
index.
A <person> is denoted with two tags <persName> for its name in both
languages : German and French. The attribute @xml:lang is used to
specify the language in ISO 639
format ("de" for German and "fr" for French).
The link to an online repository is given in the <idno> tag. We
principally use VIAF (Virtual International
Authority File). Where the person does not exist in this repository, we
can link it to Wikidata,
dataBNF or Biblissima
for example.
The nationality is given with the element <nationality> in French and
German thanks the attribute @xml:lang.
There are several <occupation> tags with the attribute @type and the
value "category" to denote each occupation of the person during his or
her life. It is repeated as much as necessary.
Two elements "note" give more information about this person in both languages.
The birth and death dates and places are given in <birth> and
<death> tags inside a <date> and a <placeName> element.
Example:
<listPerson>
<person xml:id="textgrid:3pgcb" type="identified">
<idno xml:base="https://viaf.org/viaf/7399719" type="viaf"/>
<persName xml:lang="de">Montespan, Françoise-Athénaïs de Rochechouart de Mortemart, Marquise de</persName>
<persName xml:lang="fra">Montespan, Françoise-Athénaïs de Rochechouart de Mortemart, marquise de</persName>
<nationality xml:lang="fra">français</nationality>
<nationality xml:lang="de">französisch</nationality>
<occupation type="category" xml:lang="fra">favorite / maîtresse de Louis XIV</occupation>
<occupation type="category" xml:lang="de">Marquise seit 1663</occupation>
<occupation type="category" xml:lang="de">Mätresse Ludwigs XIV. seit
1667</occupation>
<note type="description" xml:lang="fra"><p>maîtresse de Louis XIV</p></note>
<note type="description" xml:lang="de"><p> Herrin von Ludwig XIV.
</p></note>
<birth>
<date xml:lang="de">1640-10-05 (1641 ?)</date>
<date xml:lang="fra">1640-10-05 (1641 ?)</date>
<placeName>Lussac-les-Châteaux (Frankreich / France) 1034148 ?
(Tonnay-Charente (Frankreich / France)</placeName>
</birth>
<death>
<date xml:lang="de">1707-05-27</date>
<date xml:lang="fra">1707-05-27</date>
<placeName xml:lang="fra">Bourbon-l'Archambault (Frankreich / France)</placeName>
</death>
</person>
</listPerson>
This structure is the same for each person.
Index of places
This index is built on the same model as the person index with the tags
<listPlace> and <place>. The tag <place> is typed with the two
values "identified" or "unidentified" and subtyped with one of the ten
following values: "military", "religious", "domestic", "interior",
"public", "garden", "monuments", "geographic", "infrastructure",
"other". It uses an @xml:id on the same model as the person tag.
A <place> comprises four tags <placeName> typed "current" or
"historical", each in both languages French and German with an
@xml:lang.
The link to an online repository is given in an <idno> tag. We
principally use Wikidata for places and in
few cases the Getty
TGN (Getty
Thesaurus of Geographic Names).
GPS coordinates are given inside the couple tags <location> and
<geo>.
There are several <note> tags with different types to describe a
place. Each one is duplicated for the French and the German versions.
The first one specifies whether the place has always existed, with the
attribute @type and the value "state". The second one determines the
function of the place with the attribute @type and the value "function".
The third gathers the artists working at the place at the end of the
17th century and the beginning of the 18th century. This note has
the attribute @type with the value "artist". Each person is encoded with
the <persName> tag and a link to VIAF is given where possible. Where
the artist is already mentioned in our texts, we give its TextGridID in
the attribute @ref inside the <persName> tag. The fourth note gives a
description of modifications of this place with the attribute @type and
the value "event". The last note is a description of the place with the
attribute @type and the value "description".
Example:
<listPlace>
<place xml:id="textgrid:3pff1" type="identified" subtype="domestic">
<idno xml:base="https://www.wikidata.org/wiki/Q3145712" type="wikidata"/>
<placeName type="historical" xml:lang="fra">hôtel d'Angoulême</placeName>
<placeName type="historical" xml:lang="de">Hôtel d'Angoulême</placeName>
<placeName type="current" xml:lang="fra">Paris, hôtel Lamoignon</placeName>
<placeName type="current" xml:lang="de">Paris, Hôtel Lamoignon</placeName>
<note type="state" xml:lang="fra">conservé</note>
<note type="state" xml:lang="de">erhalten</note>
<note type="function" xml:lang="fra">hôtel particulier</note>
<note type="function" xml:lang="de">Hôtel particulier</note>
<note type="artist">
<persName><Philibert de L'orme
(https://viaf.org/viaf/205549982)></persName>
<persName><Thibault Métezeau
(https://www.wikidata.org/wiki/Q3524037)></persName>
<persName><Jean Thiriot (https://viaf.org/viaf/247691052)></persName>
</note>
<note type="event" xml:lang="fra">1585: début des travaux; 1589: fin des
travaux; 1624-1640: modifications</note>
<note type="event" xml:lang="de">1585: Baubeginn; 1589: Bauende; 1624-1640:
Umbauphase</note>
<location>
<geo>48.85703199999999,2.361833299999944</geo>
</location>
<note type="description" xml:lang="fra">Construit en 1585-1589 puis repris en
1611, le premier état de l'hôtel de Lamoignon est attribué à Thibault
Métezeau. Il a été anciennement attribué à Philibert Delorme. Des
modifications sont réalisées entre 1624 et 1640 par les entrepreneurs
François Boullet et Jean Thiriot. [AJ]</note>
</place>
</listPlace>
This structure is the same for each place.
Index of works
The index of works is built on the same model but this time with one
element <item> per work included in an element <list>. The tag
<item> is typed with the two values "identified" or "unidentified" and
subtyped with the values "sculpture", "painting", "book", "engraving",
"others". It uses an @xml:id like for the <person> and <place>
names.
A first <note> tag with an attribute @type is used to give the name of
the artist of the work.
The name of the work is encoded in a <name> tag in both languages and
the date in a <date> tag.
The link to an online repository is given in an <idno> tag. We used
several reference and collections databases, including: Wikidata, the
Louvre collections, the Versailles collections, AGORHA, Gallica...
The location of the work is given in <location> and <placeName>.
Where this place has already been mentioned in our texts, we give its
TextGridID in an attribute @ref inside a <placeName> tag.
There are several <note> tags with different types to describe a work.
Each one is duplicated for the French and the German versions. The first
one specifies whether the work always existed or not, with the attribute
@type and the value "state". The second one specifies the material of
the work with the attribute @type and the value "material". The third
gives the dimensions with the attribute @type and the value
"dimensions". The last one is a description of the place with the
attribute @type and the value "description".
Example:
<item xml:id="textgrid:3pfbf" type="identified" subtype="sculpture">
<name type="painting" xml:lang="fra">Statue équestre de Louis XIII</name>
<name type="painting" xml:lang="de">Reiterstatue von Ludwig XIII.</name>
<note type="artist">
<persName ref="textgrid:3q1p0"><Da Volterra, Daniele
(textgrid:3q1p0)></persName>
<persName ref="textgrid:3pg5v"><Biard, Pierre le Jeune
(textgrid:3pg5v)></persName>
</note>
<date xml:lang="fra">1639</date>
<date xml:lang="de"/>
<note type="state" xml:lang="fra">détruite</note>
<note type="state" xml:lang="de">zerstört</note>
<location type="former">
<placeName ref="textgrid:3pfpc">Paris, Place des Vosges / Paris, place des
Vosges (textgrid:3pfpc)</placeName>
</location>
<note type="material" xml:lang="fra">bronze</note>
<note type="material" xml:lang="de">Bronze</note>
<note type="dimensions" xml:lang="de">366 cm</note>
<note type="dimensions" xml:lang="fra">366 cm</note>
<note type="description" xml:lang="fra"><p>L'ensemble fut détruit le 11
août 1792 et remplacé en 1829 par une statue équestre en marbre due à
Louis-Marie-Charles Dupaty et Jean-Pierre Cortot.</p></note>
<note type="description" xml:lang="de"><p>Das Ensemble wurde am 11. August
1792 zerstört und 1829 ersetzt durch ein marmornes Reiterdenkmal von
Louis-Marie-Charles Dupaty und Jean-Pierre Cortot.</p></note>
</item>
This structure is the same for each work.
Authors of the “Encoding guidelines”: Axelle Janiak, Mathieu Duboc
Copyediting: Alexandra Pioch, Emer Lettow
Current version published on 22 September 2021
Le site d’édition numérique ARCHITRAVE comporte une rubrique «
Index » accessible dans
le menu « Édition », proposant trois index regroupant la quasi-totalité
des noms de personnes, lieux et œuvres cités dans les textes. Les trois
types d’entrées d’index y sont signalés par des symboles distincts (voir
le menu pop-up « Informations éditoriales »
 dans la barre d’outils horizontale, à l’intérieur de chaque édition).
dans la barre d’outils horizontale, à l’intérieur de chaque édition).

Chaque index comporte une table alphabétique et une rubrique intitulée « non identifié », regroupant tous les noms de personnes, de lieux ou d’œuvres n’ayant pas pu être identifiés.
Les notices sont structurées de la même façon pour les trois index :
- une section « Informations générales » reprenant les informations principales de l’entrée d’index ;
- une section « Informations complémentaires » proposant une description et des références bibliographiques ;
- une section « Occurrences » listant toutes les occurrences d’une
entrée dans l’ensemble des six textes ainsi que les occurrences liées
à d’autres index :
- Dans une notice de « personne », il est possible de voir tous les lieux et œuvres auxquels le nom de cette personne est associé.
- Dans une notice de « lieu », il est possible de voir toutes les œuvres qui se trouvaient ou se trouvent encore dans ce lieu.
L’identification des personnes, lieux et œuvres a été réalisée par les éditeurs et éditrices scientifiques du projet et des assistants de recherche (voir dans la rubrique corpus de sources la liste des collaborateurs et collaboratrices de chaque texte édité). Ces index n’ont pas vocation à constituer une base de données exhaustive, mais à fournir des informations de base vérifiées tout en renvoyant à des sources d’information complémentaires. Chaque fois que cela a été possible, nous avons indiqué un lien vers un référentiel en ligne et proposé des références bibliographiques.
Les index en chiffres :
- 791 personnes au total dont 163 non identifiées ;
- 1 415 lieux au total dont 1 245 sont géolocalisés et 130 n’ont pas pu être identifiés ;
- 546 œuvres au total dont 72 non identifiées.
Index des noms de personnes
Ont été indexées toutes les personnes citées dans les éditions, qu’elles aient ou non un patronyme ou un prénom, à l’exception des personnes représentées dans des œuvres d’art, des personnages littéraires, mythologiques ou bibliques. Certains saints ont été indexés lorsque cela s’est avéré utile pour la compréhension du texte.
Informations générales
Catégorie : les personnes ont été réparties dans les six catégories ci-dessous. Seules 33 personnes indexées (non identifiées) n’ont pu être réparties dans une catégorie.
| Catégorie en français | Catégorie en allemand | Identifiés | Non identifiés | Total |
|---|---|---|---|---|
| Dirigeants et princes | Herrscher und Fürsten | 134 | 1 | 135 |
| Membres du gouvernement et de l’administration | Regierungs- und Verwaltungsmitglieder | 120 | 21 | 141 |
| Savants et hommes de lettres | Gelehrte und Schriftsteller | 41 | 0 | 41 |
| Ecclésiastiques | Kirchliche Würdenträger | 56 | 5 | 61 |
| Artistes | Künstler | 232 | 4 | 236 |
| Autres | Andere | 45 | 99 | 144 |
| (sans catégorie) | (Ohne Kategorie) | 0 | 33 | 33 |
| Total | 628 | 163 | 791 |
Référentiel : nous avons utilisé les référentiels Biblissima, Kaiserhof und Höfe (base de données), VIAF, Wikidata (voir plus bas la liste exhaustive des ressources documentaires et électroniques).
Nationalité : nous avons dû parfois préciser, par exemple : autrichienne (Bohême) ; autrichienne (Habsbourg d’Autriche) ; britannique (maison de Hanovre) ; espagnole (maison de Habsbourg) ; italienne (Savoie) ; flamande (Pays-Bas espagnols) ; flamande (principauté de Liège) ; néerlandaise (Pays-Bas bourguignons) pour la période antérieure à 1580 ; néerlandaise (Provinces-Unies) pour la période postérieure à 1580.
Fonction(s) : nous avons indiqué jusqu'à quatre fonctions différentes ; pour les personnes de l'époque des auteurs, nous nous sommes concentrés sur les fonctions exercées durant la période des textes édités. Nous avons également mentionné ici les titres de noblesse et titres de familles princières.
Date de naissance/décès : saisies au format année/mois/jour (AAAA-MM-JJ).
Lieu de naissance/décès : nous avons indiqué les noms de villes et de pays actuels.
Informations complémentaires : 293 sur 751 personnes indexées comportent une description. On trouve ici des compléments d’information sur les fonctions exercées, des références bibliographiques (avec le lien vers la source numérisée lorsqu’elle est disponible) ayant permis de compléter l’identification d’une personne, des informations sur des liens matrimoniaux, de parenté ou autres (dynasties d’artistes ou liens maître/élève), ainsi que des renvois vers d’autres bases (base biographique du Centre de recherche du château de Versailles ; RKDartists&). Dans le cas des personnes non identifiées, une hypothèse d’identification peut être proposée avec une source.
Rubrique « non identifié » : lorsqu’une personne est citée dans un texte sans mention de son patronyme ou de son prénom, nous avons indiqué dans l’intitulé principal de la notice le titre, la fonction, ou encore la nationalité mentionnés par l’auteur.
Exemple de notice « personne »
Index des noms de lieux
Au-delà des lieux géographiques, cet index regroupe avant tout les édifices et œuvres architecturales (voir la liste des catégories ci-dessous) à l’exception des sculptures, recensées dans l’index des œuvres.
Informations générales
Catégorie : les noms de lieux ont été classés dans les dix catégories ci-dessous, qui sont également utilisées pour la visualisation des itinéraires des voyageurs en Europe et en France (voir l’entrée « Itinéraires des voyageurs » dans le menu « Visualisations » du portail) – à l’exception de celle des « Édifices domestiques (intérieurs) ».
| Catégorie en français | Catégorie en allemand | Contenu de la catégorie | Identifiés | Non identifiés | Total |
|---|---|---|---|---|---|
| Lieux géographiques | Geografische Orte | continent, pays, île naturelle, cours d’eau, montagne, plaine, ville, village, hameau... | 398 | 1 | 399 |
| Infrastructures | Infrastruktur | avenue, allée, cours, boulevard, rue, ruelle, port, quai, porte, tour, place, fontaine, pompe, faubourg, quartier, île (Paris), pont, aqueduc, tunnel, réservoir, darse, canal... | 215 | 26 | 241 |
| Édifices publics | Öffentliche Gebäude | académie, hôtel de ville, arènes, théâtre, bibliothèque, opéra, observatoire, prison, gibet, jeu de paume, thermes, collège, université, faculté, hôtel des Monnaies, foire, marché, bourse, manufacture royale... | 72 | 8 | 80 |
| Monuments | Monumente | arc de triomphe, colonne, obélisque, pyramide | 10 | 2 | 12 |
| Édifices domestiques | Wohngebäude | palais, maison, hôtel particulier, château, cabinet (de collectionneur, de curiosités), bibliothèque de particulier | 168 | 16 | 184 |
| Édifices domestiques (intérieurs) | Wohngebäude (Innenräume) | division à l’intérieur d’une résidence | 97 | 11 | 108 |
| Édifices religieux | Religiöse Gebäude | chapelle, église, cathédrale, couvent, abbaye, séminaire, monastère, noviciat, basilique, hôpital, nécropole, cimetière, institution religieuse... | 197 | 18 | 215 |
| Constructions militaires | Militäreinrichtungen | arsenal, fort, bastion, citadelle, forteresse, caserne(s), dépôt d’armes et de munitions, fonderie... | 52 | 0 | 52 |
| Parcs et jardins | Parks und Gärten | jardin, parc, bosquet, bassin, pièce d’eau, étang, orangerie, ménagerie, pavillon de jardin, grotte | 70 | 4 | 74 |
| Autres lieux | Andere Orte | filature, moulin, verrerie, abattoir, halle aux draps, auberge, hôtellerie, relais de poste, Maison de corporations... | 6 | 44 | 50 |
| Total | 1285 | 130 | 1415 |
Référentiel : nous avons utilisé les référentiels data.bnf, Getty Thesaurus of Geographic Names (TGN) et Wikidata (voir plus bas la liste exhaustive des ressources documentaires et électroniques)
Nom actuel : le nom sous lequel le lieu ou l’édifice est identifié aujourd’hui.
Nom historique : le ou les noms donnés à l’époque s’ils diffèrent du nom actuel ; il peut aussi s’agir de noms historiques ou d’autres appellations d’usage à l’époque.
Fonction(s) : cette section est renseignée pour les hôtels particuliers, les résidences royales, et dans le cas où l’intitulé du lieu ou de sa catégorie n’est pas suffisamment explicite ; on précise ici aussi les changements d’affectation d’édifices au cours des XVIIe et XVIIIe siècles, et dans quelques rares cas jusqu’à l’époque actuelle.
État actuel : le « lieu » peut être conservé ou partiellement conservé, détruit ou partiellement détruit, dissous (académies ou collèges par exemple), dispersé (collections dans des cabinets).
Artiste(s)/Auteur(s) : cette liste non exhaustive mentionne, quand
cela est possible, les principaux architectes, peintres et sculpteurs de
l’édifice, dans la limite de trois artistes. La mention « et al. » a été
ajoutée dans certains cas pour les édifices dont nous savons que la
construction a nécessité le travail d’un nombre supérieur d’artistes,
que ceux-ci soient ou non identifiés (cathédrales, résidences royales
notamment...). Lorsque les artistes mentionnés dans cette section sont
également présents dans l’index des personnes, le symbole correspondant
 s’affiche
; dans les autres cas, nous renvoyons vers un référentiel (quand il est
disponible), signalé par le
symbole
s’affiche
; dans les autres cas, nous renvoyons vers un référentiel (quand il est
disponible), signalé par le
symbole .
.
Chronologie : elle indique les principales dates de construction, modifications et destructions jusqu’à la fin du XVIIIe siècle et dans certains cas au-delà (destructions et reconstructions importantes intervenues par exemple au XIXe siècle, ou du fait de la Seconde Guerre mondiale, incendie de Notre-Dame en 2019...).
Géolocalisation : coordonnées géographiques (latitude, longitude) en degrés décimaux (DD), renvoyant vers Google Maps. Ces coordonnées ont été utilisées pour la visualisation des itinéraires et des lieux visités par les voyageurs (voir dans le menu Visualisations > Itinéraires des voyageurs). Pour les divisions à l’intérieur de bâtiments ou de jardins, nous avons (à quelques exceptions près) repris la géolocalisation de l’édifice principal. Pour les institutions (académies notamment), nous n’avons pas indiqué de géolocalisation, celles-ci ayant pu déménager ou occuper plusieurs sites.
Informations complémentaires : 367 lieux sur les 1 403 indexés comportent une description. Nous avons choisi de nous concentrer sur certains d’entre eux, surtout les moins connus (édifices religieux, hôtels particuliers, quelques places, portes et ponts, une sélection de monuments et d’intérieurs de résidences et châteaux). Nous n’avons pas commenté les lieux très connus, les référentiels renvoyant vers suffisamment de ressources. Pour certains lieux pour lesquels il n’existait pas de ressource fiable ou récente, nous avons parfois renvoyé vers Germain Brice (Description nouvelle de la ville de Paris, éditions de 1698 et 1706), Pierre Le Muet (Manière de bien bastir pour toutes sortes de personnes, Paris, F. Langlois, 1647) ou une autre source de l’époque. Nous ajoutons dans cette section une précision lorsque les voyageurs ont commenté le décor de l’intérieur du bâtiment (peintures murales, plafonds...) : le lecteur peut ainsi consulter l’occurence correspondante.
Nous n’avons pas indexé séparément les couvents/abbayes et leurs églises, mais conservé une seule entrée renvoyant au couvent ou à l’abbaye : la plupart du temps ce sont les églises conventuelles ou abbatiales qui sont visitées par les voyageurs.
Exemple de notice « lieu »
Index des noms d’œuvres
Seules ont été indexées les œuvres mobiles, en excluant donc les peintures murales, fresques, plafonds peints et autres décors fixes pour ne pas alourdir davantage cet index. Des informations sur ces éléments décoratifs peuvent se trouver dans les « Informations complémentaires » des entrées concernées des index des lieux et des œuvres (on trouvera par exemple une description succincte de la coupole du Val-de-Grâce dans l’index des lieux, sous Paris, abbaye du Val-de-Grâce ; les tentures de l’Histoire de saint Gervais et saint Protais sont évoquées dans la notice « lieu » Paris, église Saint-Gervais-Saint-Protais).
Informations générales
Catégorie : les œuvres ont été réparties dans les cinq catégories ci-dessous.
| Catégorie en français | Catégorie en allemand | Identifiés | Non identifiés | Total |
|---|---|---|---|---|
| Peinture | Malerei | 222 | 31 | 252 |
| Sculpture | Plastik | 146 | 21 | 167 |
| Gravure | Graphik | 41 | 6 | 47 |
| Livres | Bücher | 42 | 1 | 43 |
| Autres | Andere | 24 | 13 | 37 |
| Total | 475 | 72 | 546 |
Référentiel : nous avons utilisé la base de données AGORHA de l’INHA, le catalogue de la BnF, HEIDI, Gallica, l’OBVSG (Österreichischer Bibliothekenverbund und Service GmbH), VIAF, Wikidata, les bases de données des Collections du château de Versailles et des Collections du musée du Louvre, la bibliothèque numérique de l’INHA, le Catalogue des sculptures des jardins de Versailles et de Trianon (voir plus bas la liste exhaustive des ressources documentaires et électroniques).
Artiste(s)/Auteur(s) : lorsque les artistes mentionnés dans cette
section sont également présents dans l’index des personnes, le symbole
correspondant
s’affiche ; dans les autres cas, nous renvoyons vers un référentiel
(quand il est disponible), signalé par le symbole
.
Date(s) : date(s) de réalisation de l’œuvre.
État actuel : dans cette section nous indiquons, selon le cas, conservé/partiellement conservé ; détruit/partiellement détruit ; disparu ; exécuté en partie.
Localisation actuelle : le lieu où l’œuvre est conservée aujourd’hui
; lorsqu’il est indexé dans l’index des lieux, il est signalé par le
symbole .
.
Localisation ancienne : la plupart des lieux dans lesquels se
trouvaient les œuvres indexées sont présents dans l’index des lieux et
signalés par le
symbole.
Matières et techniques : sont précisées ici les différentes matières et techniques utilisées.
Dimensions : données en centimètres (le plus souvent hauteur et largeur) ; pour les œuvres complexes (monuments funéraires composés d’un grand nombre d’éléments), nous indiquons en général les dimensions globales et/ou celles de certaines sculptures importantes.
Informations complémentaires : 504 œuvres sur 546 comportent une description. Celle-ci livre pour l’essentiel des informations contextuelles et matérielles (circonstances de la commande et état de conservation). Par nature moins connues, les œuvres détruites ou disparues bénéficient souvent d’une description plus longue visant à faire mieux connaître leur histoire.
Exemple de notice « œuvre »
Ressources documentaires et électroniques
Voici la liste de l’ensemble des ressources électroniques utilisées pour l’établissement des trois index (référentiels, catalogues de bibliothèques, thesaurus, inventaires, portails de collections, etc.). Nous précisons que la bibliographie exhaustive du projet ARCHITRAVE est disponible dans le le menu « Édition » dans la rubrique « Bibliographie »
Ressources générales
- Authority records for persons, printers, corporate entities and places until approx. 1830 (CERL Thesaurus) : https://data.cerl.org/thesaurus/_search
- Data.bnf.fr (Fiches de référence sur les auteurs, les œuvres et les thèmes de la BnF) : https://data.bnf.fr
- Identifiants et Référentiels pour l’enseignement supérieur et la recherche (IdRef) : https://www.idref.fr/
- Virtual International Authority File (VIAF) : https://viaf.org/
- Wikidata : https://www.wikidata.org/
- Wikipédia : https://fr.wikipedia.org/
Ressources spécifiques
Personnes
- Annuaire prosopographique de la France savante (CTHS) : http://cths.fr/an/prosopographie.php
- Base biographique du Centre de recherche du château de Versailles : http://www.chateauversailles-recherche-ressources.fr/jlbweb/jlbWeb?html=accueildictionnaire
- Base de données « Acteurs » de l’époque moderne, projet Symogih : http://symogih.org/?q=actors-list&lang=fr
- Bases de données « personnes » AGORHA de l’INHA : https://agorha.inha.fr/
- Biblissima. Observatoire du patrimoine écrit du Moyen Âge et de la Renaissance : https://biblissima.fr/
- Biografisch Portaal van Nederland : http://www.biografischportaal.nl/
- Deutsche Biographie : https://www.deutsche-biographie.de/
- Deutsche Nationalbibliothek (DNB): https://www.dnb.de/DE/Home/home_node.html
- Germania Sacra - Digital Index of Persons : http://germania-sacra-datenbank.uni-goettingen.de/
- Getty Union List of Artist Names (ULAN) : https://www.getty.edu/research/tools/vocabularies/ulan/
- Kunstindeks Danmark / Weilbach Dansk Kunstnerleksikon : https://www.kulturarv.dk/
- Base de données sur les courtisans des Habsbourg d’Autriche, 16e et 17e siècles : https://kaiserhof.geschichte.lmu.de/
- Bases Architecture et Patrimoine du ministère de la Culture et de la Communication : http://www2.culture.gouv.fr/culture/inventai/patrimoine/
- Répertoires biographiques d’artistes : https://bnf.libguides.com/artiste
- Repertorium der diplomatischen Vertreter aller Länder seit dem Westfälischen Frieden (1648), vol. I, 1648-1715, sous la dir. de Ludwig Bittner et Lothar Groß, avec la collaboration de Walther Latzke, Oldenburg et Berlin, Gerhard Stalling, 1936
- Repertorium der diplomatischen Vertreter aller Länder seit dem Westfälischen Frieden (1648), vol. II, 1716-1763, Friedrich Hausmann, sous la dir. de Leo Santifaller, avec la collaboration de Lothar Groß et Edith Kotasek, Zurich, Fretz & Wasmuth, 1950
- Database of Dutch and Foreign artists from the Middle Ages to today (RKDartists), mis à disposition par le Rijksbureau voor Kunsthistorische Documentatie à La Haye : https://rkd.nl/en/explore/artists
Lieux
- Archinform – Base de données d’architecture internationale : https://fra.archinform.net
- Archipedie – Encyclopédie numérique collaborative sur l’architecture moderne et contemporaine : http://archipedie.citedelarchitecture.fr/
- Base de données des collections du musée des Monuments français : https://collections.citedelarchitecture.fr/
- Base Mérimée (patrimoine architectural) : https://www.pop.culture.gouv.fr/search/list?base=%5B%22Patrimoine%20architectural%20%28M%C3%A9rim%C3%A9e%29%22%5D
- Carte de France de Cassini : http://cassini.ehess.fr/cassini/fr/html/index.htm
- Census of Antique Works of Art and Architecture Known in the Renaissance : https://database.census.de/search
- Corpus des hôtels parisiens du XVIIe siècle : inventaires après décès de 24 hôtels : https://www.centrechastel.sorbonne-universite.fr/ressources/ressources-documentaires/corpus-et-bases-de-donnees/sources-et-corpus-publies-en-ligne
- Corpus Inscriptionum Latinarum : https://fr.wikipedia.org/wiki/Corpus_Inscriptionum_Latinarum
- Dictionnaire topographique de la France (CTHS) : https://dicotopo.cths.fr/
- EDCS Epigraphik-Datenbank Clauss / Slaby : http://db.edcs.eu/epigr/epi.php?s_sprache=fr
- Forte Cultura - L’itinéraire culturel monuments fortifiés : https://www.forte-cultura.eu/en/festungen-en/architektur/stadtfestungen
- Geonames : http://www.geonames.org/
- Geoportail : https://www.geoportail.gouv.fr/
- Getty Thesaurus of Geographic Names (TGN) : https://www.getty.edu/research/tools/vocabularies/tgn
- Glossaire de l’édition numérique de François Lemée, Traité des Statuës, Paris, 1688, éd. critique par Diane H. Bodart et Hendrik Ziegler, Weimar, VDG, 2012 : https://asw-verlage.de/lemee (accès sur abonnement uniquement)
- Liste des églises disparues de Paris : https://fr.wikipedia.org/wiki/Liste_des_%C3%A9glises_disparues_de_Paris
- Liste des hôtels particuliers parisiens : https://fr.wikipedia.org/wiki/Liste_des_h%C3%B4tels_particuliers_parisiens ; https://commons.wikimedia.org/wiki/List_of_h%C3%B4tels_particuliers_in_Paris
- Observatoire du patrimoine religieux – Inventaire : https://www.patrimoine-religieux.fr/
- Old Maps online : https://www.oldmapsonline.org/
- Paris Data – Voies, nomenclature des voies actuelles : https://opendata.paris.fr/explore/dataset/denominations-emprises-voies-actuelles/information/?disjunctive.siecle&disjunctive.statut&disjunctive.typvoie&disjunctive.arrdt&disjunctive.quartier&disjunctive.feuille
- POP, la plateforme ouverte du patrimoine : https://www.pop.culture.gouv.fr/
- Registres de la Comédie-Française : https://www.cfregisters.org/
- Structurae – Base de données et galerie internationale d’ouvrages d’art et du génie civil : https://structurae.net/
Œuvres
- Bases de données AGORHA de l’INHA : https://agorha.inha.fr/
- Base de données des Collections du château de Versailles : http://collections.chateauversailles.fr/
- Base de données des Collections du musée du Louvre : https://collections.louvre.fr/
- Banque d’images du Centre de recherche du château de Versailles : http://www.banqueimages.chateauversailles-recherche.fr/
- Bases de données du Centre de recherche du château de Versailles (Base bibliographique et Base biographique) : http://www.chateauversailles-recherche-ressources.fr/jlbweb/jlbWeb?html=accueilarticles ; http://www.chateauversailles-recherche-ressources.fr/jlbweb/jlbWeb?html=accueildictionnaire
- Bibliothèque numérique de l’INHA : https://bibliotheque-numerique.inha.fr/
- Catalogue de la BNF : https://catalogue.bnf.fr/
- Catalogue des sculptures des jardins de Versailles et de Trianon : https://sculptures-jardins.chateauversailles.fr/
- Census of Antique Works of Art and Architecture Known in the Renaissance : https://database.census.de/search
- Collections numériques de l’université de Heidelberg : https://digi.ub.uni-heidelberg.de/
- Digitaler Portrait Index : https://portraitindex.de/
- Europeana : https://www.europeana.eu/fr
- Galerie des Glaces – Catalogue iconographique (dir. Nicolas Milovanovic) : https://galeriedesglaces-versailles.fr/html/11/accueil/index.html
- Gallica : https://gallica.bnf.fr/
- HathiTrust Digital Library : https://www.hathitrust.org/
- HEIDI – Catalogue en ligne de la bibliothèque universitaire de Heidelberg : https://katalog.ub.uni-heidelberg.de/
- Digitale Sammlungen der Herzogin Anna Amalia Bibliothek, Weimar : https://haab-digital.klassik-stiftung.de/viewer/index/
- Internet Archive : https://archive.org/
- Joconde – Catalogue des collections des musées de France : https://www.pop.culture.gouv.fr/search/mosaic?base=%5B%22Collections%20des%20mus%C3%A9es%20de%20France%20%28Joconde%29%22%5D&image=%5B%22oui%22%5D
- Karlsruher Virtueller Katalog (KVK) : https://kvk.bibliothek.kit.edu
- K10plus-Verbundkatalog : https://opac.k10plus.de/
- Les vocabulaires du ministère de la Culture et de la Communication : http://data.culture.fr/thesaurus/
- Moteur Collections du ministère de la Culture : https://www.culture.fr/Moteur-Collections
- OPACplus (Bayerische Staatsbibliothek) : https://opacplus.bsb-muenchen.de/
- Österreichischer Bibliothekenverbund und Service GmbH (OBVSG) : https://www.obvsg.at/
- POP, la plateforme ouverte du patrimoine : https://www.pop.culture.gouv.fr/
- Palissy – Base patrimoine mobilier : https://www.pop.culture.gouv.fr/search/mosaic?base=%5B%22Patrimoine%20mobilier%20%28Palissy%29%22%5D&image=%5B%22oui%22%5D
- Versailles décor sculpté extérieur (dir. Béatrix Saule) : https://www.sculpturesversailles.fr/
- Virtuelles Kupferstichkabinett : http://www.virtuelles-kupferstichkabinett.de/
Auteur : Alexandra Pioch